编程开发
GDB调试秘籍:像高手一样排查问题
提升代码调试效率的必备技能指南。
算法解析
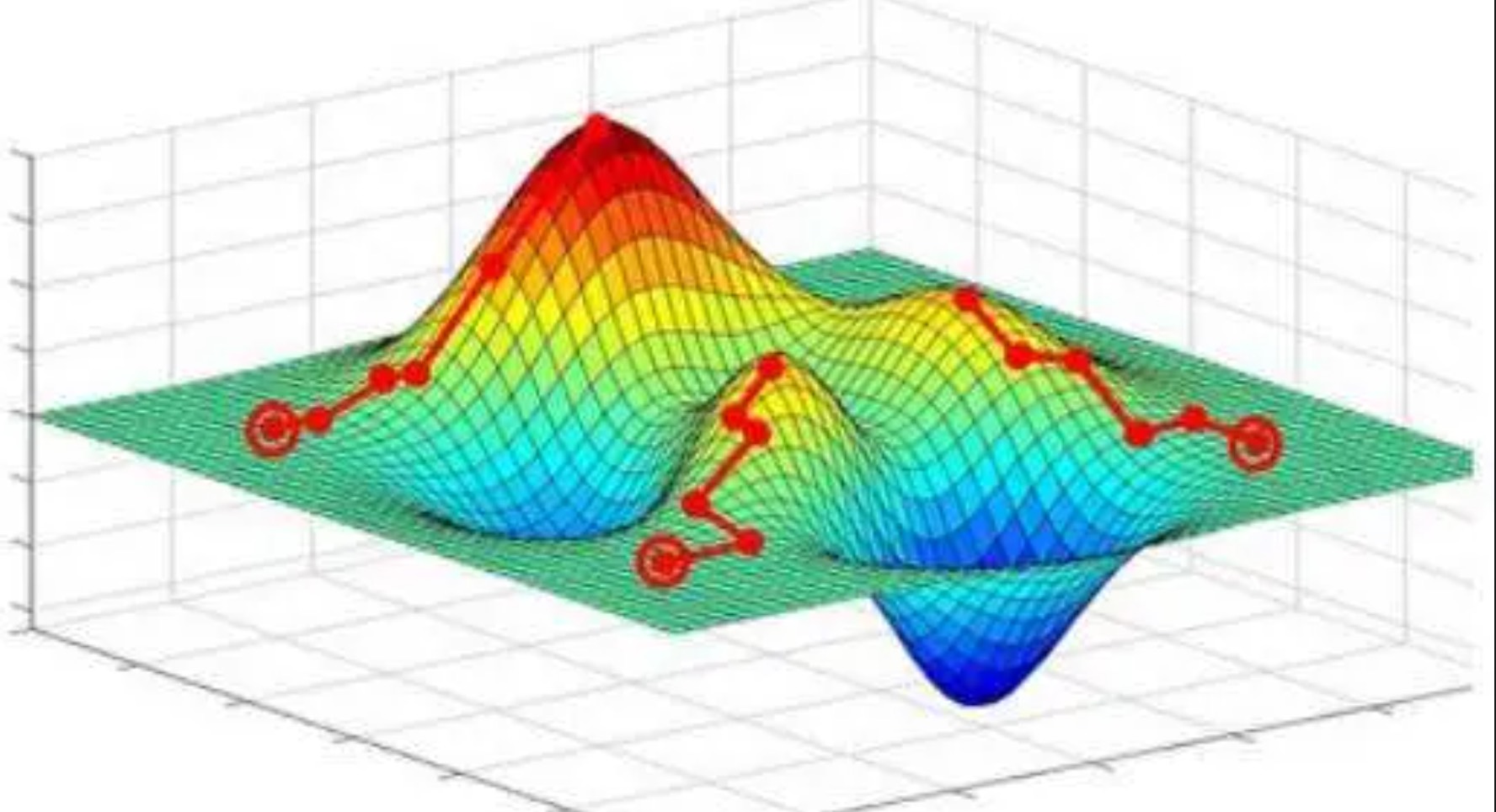
机器学习中的优化方法
梯度下降法和牛顿迭代法公式推导。
算法解析
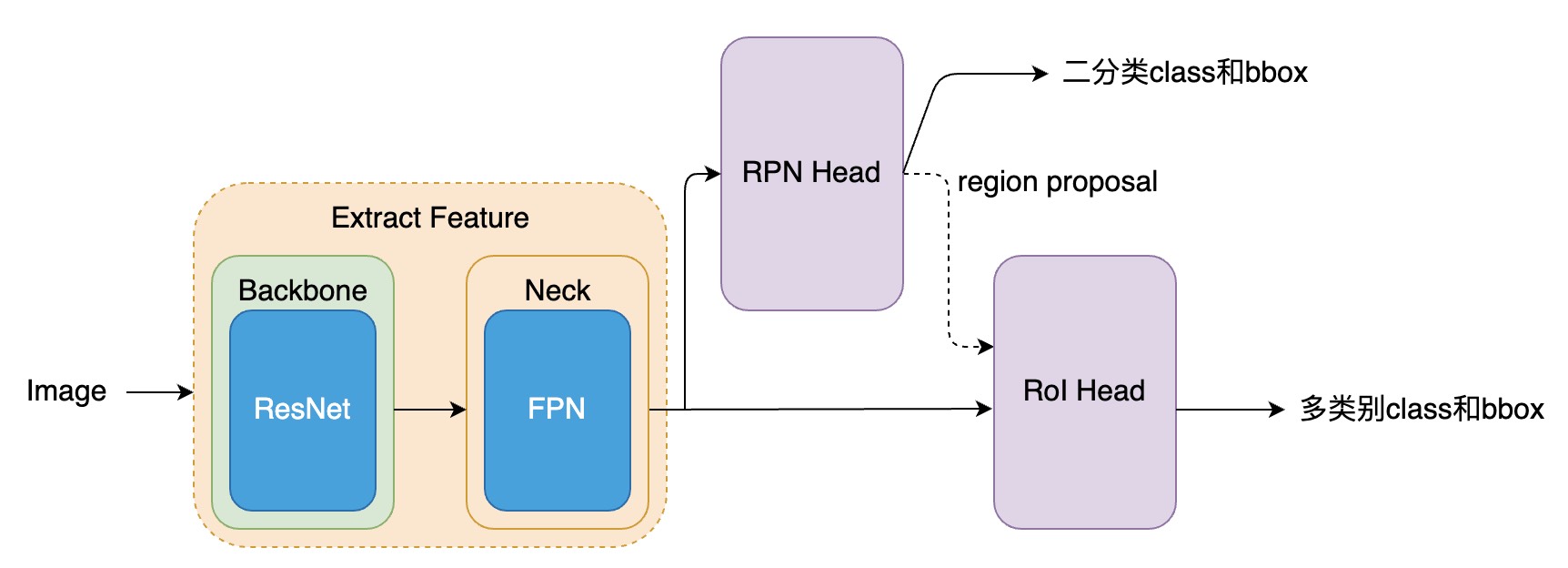
基于mmdetection源码:Faster R-CNN算法解读
Faster R-CNN算法源码解读
算法解析
LeetCode 进阶指南:解题思路与算法题分类总结
LeetCode 刷题之旅
算法解析
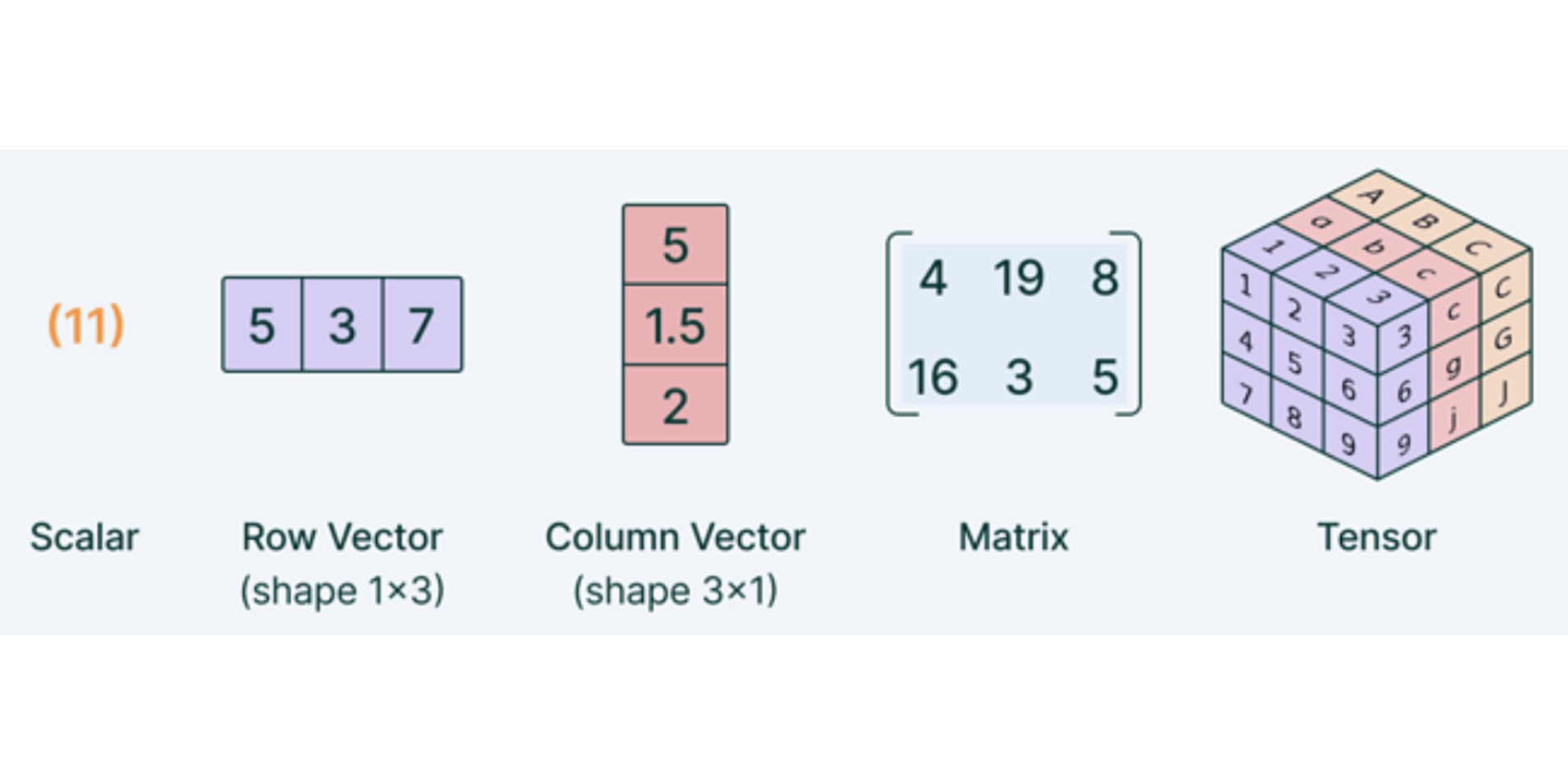
矩阵运算在深度学习中的理论与应用
从数学原理到神经网络的矩阵解析
算法解析
卷积计算底层实现
揭秘卷积背后的“矩阵魔术”
编程开发
C++知识点总结
总结C++中常用的知识点和容易混淆的用法,作为自己的一个C++使用手册来查询阅读。
算法解析
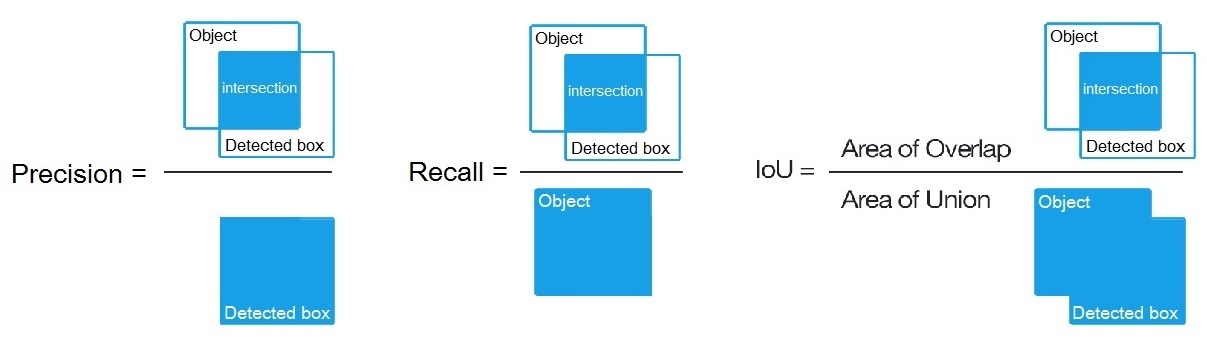
目标检测模型的评估方法
如何评估一个算法模型的检测结果是好还是不好?
算法解析
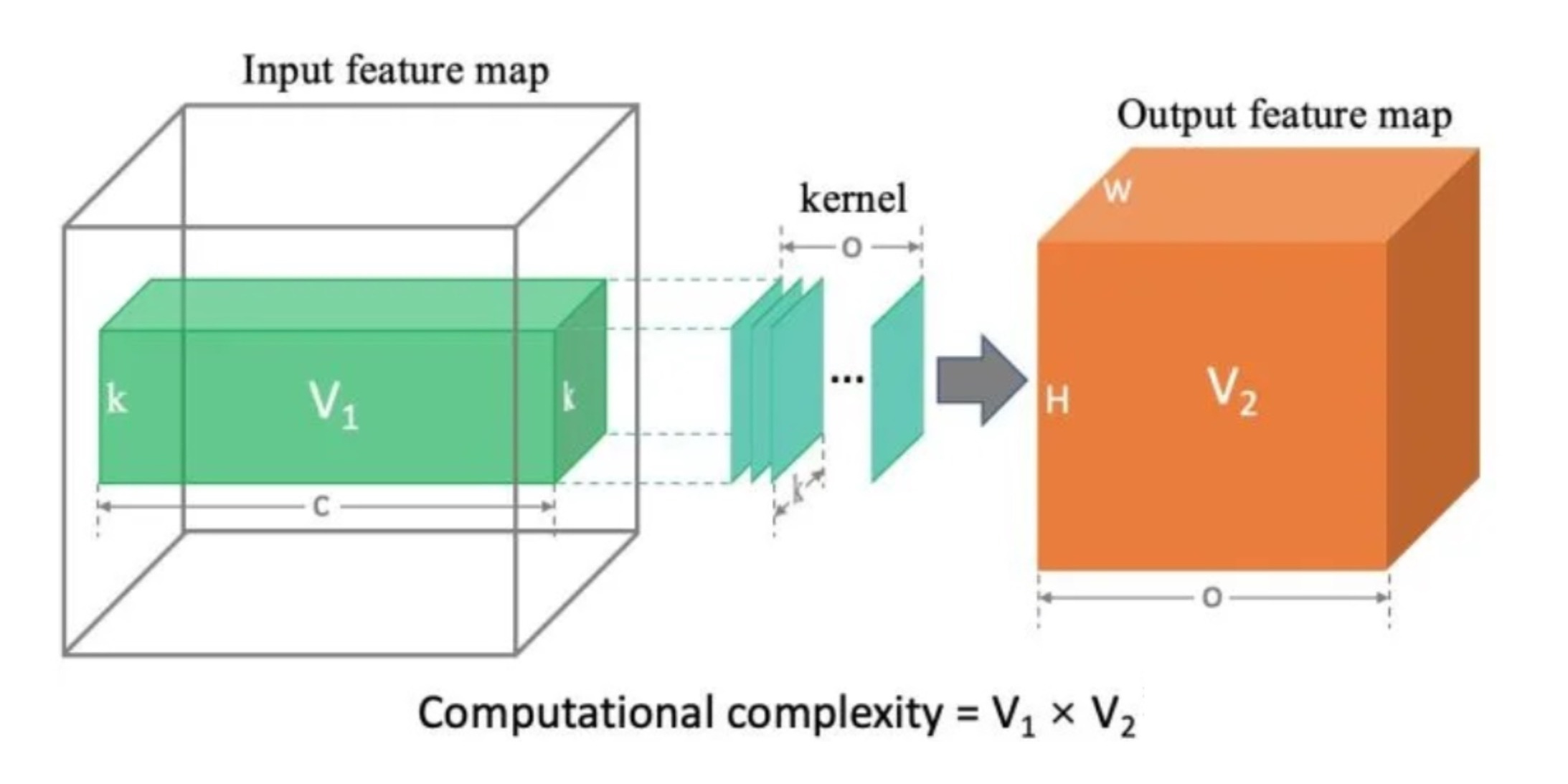
拆解神经网络算子:参数量与计算量的秘密
看懂深度学习中的计算与储存开销
算法解析
Pytorch源码阅读(三):BatchNorm Module
1
2
3
Jump to page:
(1 - 3)
Go
Enter
Press Enter to jump