
前言
支持向量机即Support Vector Machine,简称SVM。我最开始听说这个机器的时候,一头雾水,“支持”,“向量”,“机”,这三个词组合在一起让我在一开始觉得这个东西好抽象。首先,SVM实际上是一个二分类模型,也可以用来解决回归问题。了解过一些原理后,我觉得这种模型(方法)被称为Vector Support Machine更好一些,简单且不严谨的理解是: 这种模型通过某些向量(高维空间中的点)支持(支撑)而形成的一种机器(方法),或者称之为模型。
引用Free Mind在介绍SVM中一句话:“SVM 一直被认为是效果最好的现成可用的分类算法之一(其实有很多人都相信,“之一”是可以去掉的)”。刚开始接触机器学习(大半年🤦♂️),目前没有做太多实践,并不清楚SVM的效果有多好,后面应该多了解些SVM的实际应用。
支持向量机原理
现在有一些数据$\mathbf{x}={\boldsymbol{x_1}, \boldsymbol{x_2}, \boldsymbol{x_3}, …, \boldsymbol{x_n}}$,这些数据的标签也已知$\mathbf{y}={y_1, y_2, y_3, …, y_n}$。其中每个数据$\boldsymbol{x_i}$为有两个特征值,即$\boldsymbol{x_i} = (x_{i1}, x_{i2})$,为二维空间上的一点,标签$y_i\in{-1, +1}$,一般我们将$+1$称作正类,将$-1$称为负类。这里假设$\boldsymbol{x_i}$只有两个特征值是为了能够在二维坐标中将数据表示出来,方便理解。更一般地,$\boldsymbol{x}_{i} \in \mathbb{R}^{n}$,即每个数据有$n$个特征值,每个数据都是$n$维空间中的一个点。
下图在二维坐标系中将这些数据表示出来,其中红色代表正类,蓝色代表负类。
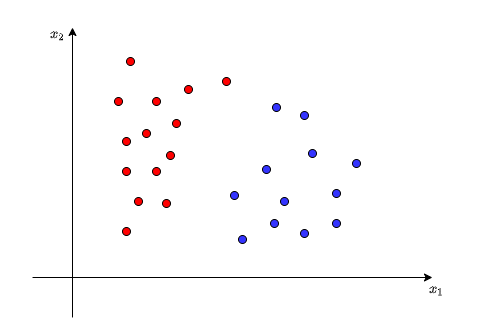
可能有人要问了:为什么这些点分布的很有规律(特点)?即正类的这些红色点都分布在一边,而蓝色的这些数据点分布在另外一边。的确,现实中的数据往往不会这么理想,可能会是两部分数据交叉在一起,并不是直观上那么明显的分为两边,这里我们从最简单的原数据线性可分的问题入手,所以先假设数据比较理想。之后我们会慢慢介绍一些复杂数据的情况是如何处理的。
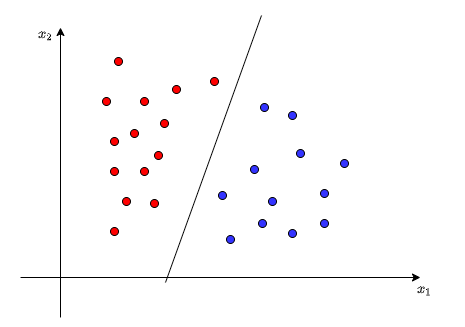
那么如果有上图一些较为理想的数据,需要寻找到一个线性边界将它们划分开来,如何找到这个线性边界呢?这个问题大概小学生也能做到。如下图,我们在红色数据点和蓝色数据点之间画一条直线,使得两类点分割到直线的两边,这条直线显然就是一个线性边界,并且可以正确地将所给的数据集分为两类。
然而,或许你想说你画出来的直线和上图不一样,它或许是下图中的某一条。
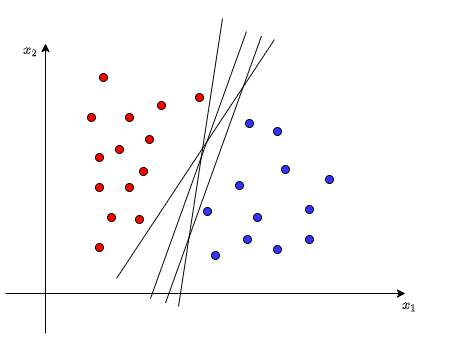
这里,我们很容易想到这样的直线有无数条。用这些直线对于已知的上图数据分类,它们的确都可以产生正确的分类结果。然而,机器学习建模的目的并不是对于已知点(标签已知)成功分类即可,学习的目的是需要对于未知情况也能够适用,即对于一个未知分类的数据点,我们的建立的模型需要告诉我们这个数据点它是属于哪一类的,正类或者是负类。机器学习建立的模型试图去寻找数据中一般的规律,而不是对于已有数据正确的表示。
假如对于一个新的未知分类的数据,它在二维坐标位置为X所在的位置如下图。
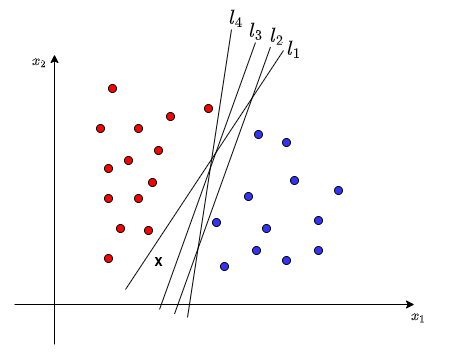
这里,我们用上面得到的这些直线对新的数据X分类,$l_1$直线和其他直线分类的结果并不一样,它处在$l_1$右侧,将它标记为负类;它处在其他直线的左侧,将它标记为正类。不同的线性模型对于新的数据的分类结果不一样,那么,如何衡量这些直线的好坏,哪一个直线最好,更能代表这些数据中的一般规律呢?
SVM给出的答案是:求解能够正确划分训练数据集并且几何间隔最大的分离超平面。 这也是SVM学习的基本想法。
这里的几何间隔最大含义是:在无数正确划分数据集的分离超平面中,找到这样的超平面,该超平面离最近的数据点的距离最大。用数学语言描述为下面的约束最优化问题: $$ \begin{array}{ll} \max \limits_{\boldsymbol{w}, \boldsymbol{b}} & \gamma \ \text { s.t. } & y_{i}\left(\frac{\boldsymbol{w}}{|\boldsymbol{w}|} \cdot \boldsymbol{x_{i}}+\frac{b}{|\boldsymbol{w}|}\right) \geqslant \gamma, \quad i=1,2, \cdots, N \end{array} $$ 其中,第一行代表优化问题中目标函数,第二行代表约束条件,$s.t.$指的是subject to ,受限于。
要理解上面的式子,让我们先来回顾下超平面的公式以及点到超平面的距离公式,可以参考这篇文章的推导超平面公式及点到超平面距离,超平面的公式为: $$ \boldsymbol{w}^{T} \boldsymbol{x}+b=0 $$ 其中,$w$是超平面的法向量,此处为列向量,简单的理解为:$w^{T} x$为法向量和超平面中的点向量(原点到超平面点形成的向量)的内积,该内积代表点向量在法向量上投影的距离;如果对超空间中的自由点施加一个法向量投影距离为$-b$时的拘束条件,那么所有满足约束条件的所有点处于超平面内。
超空间中,点到超平面的距离公式为: $$ d=\frac{|\boldsymbol{w}^{T} \boldsymbol{x}+b|}{|\boldsymbol{w}|} $$ 其中$|\boldsymbol{w}|$代表$\boldsymbol{w}$向量的第二范数,也称欧几里得范数(距离);其严格表示应该为$|\boldsymbol{w}|_2$,因为比较常用常常省略右下角标2。
让我们回到上面的SVM约束最优化问题: $$ \begin{array}{ll} \max \limits_{\boldsymbol{w}, \boldsymbol{b}} & \gamma && (1) \\ \text { s.t. } & y_{i}\left(\frac{\boldsymbol{w}}{|\boldsymbol{w}|} \cdot \boldsymbol{x_{i}}+\frac{b}{|\boldsymbol{w}|}\right) \geqslant \gamma, \quad i=1,2, \cdots, N && (2) \end{array} $$ $\gamma$代表的是数据点到超平面的几何距离,$(2)$式括号内代表的是每个点到超平面的几何距离,然而,不同于上面的距离公式,该公式没有加绝对值,括号部分的值可正可负,显然,正负对应于超平面的两侧,一开始我们有约定标签$y_i\in{-1, +1}$,那么当我们约定括号部分值为负的那一侧代表负类,即$y_i=-1$;为正的那一侧代表正类,即$y_i=+1$,这里更多的是一种约定的问题,这种约定方便我们建模求解问题。
我们可以试着理解下$(1) (2)$两式,当有某些数据点被分错时,$(2)$左侧结果为负值,那么$\gamma$也为负值,此时$\gamma$肯定不是最大值,只有当所有的数据点都被正确分类时($\gamma$为正),而且超平面距离最近的点的距离最远时,$\gamma$达到最大。也就是说,如果我们的求解方法是对参数逐步迭代达到$\gamma$最大时,那么一开始是由误分类点驱动,之后根据几何间隔最大驱动参数更新。 上面最优化建模完美得到了正确划分训练数据集并且几何间隔最大的目的。
后续讨论:
- 数据并不是线性可分的。
- 数据存在误差,软间隔。
SVM优缺点
优点
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
缺点
- 训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为$O\left(N^{2}\right)$,其中 N 为训练样本的数量;
- 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为$O\left(N^{2}\right)$;
- 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
- 目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
SVM使用场景
现有的一些支持向量机软件包
LIBSVM – A Library for Support Vector Machines