前言
如何评价一个算法模型的检测结果是好还是不好呢?
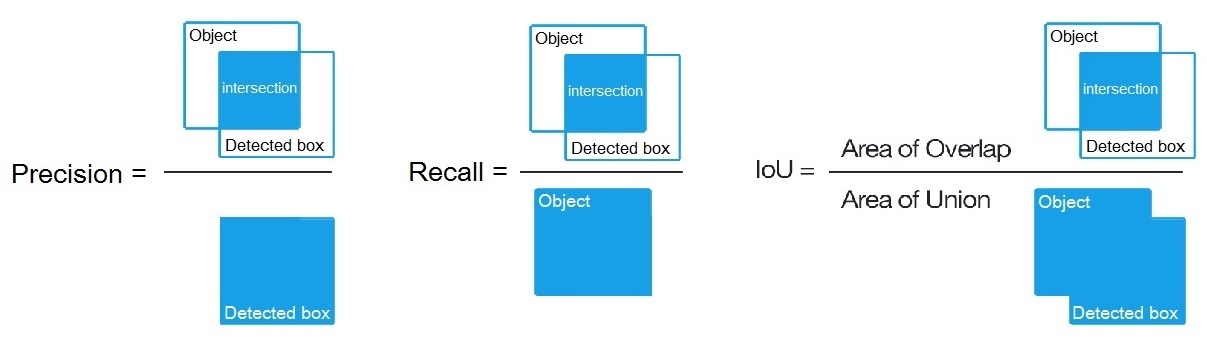
检测结果的正确/错误类型
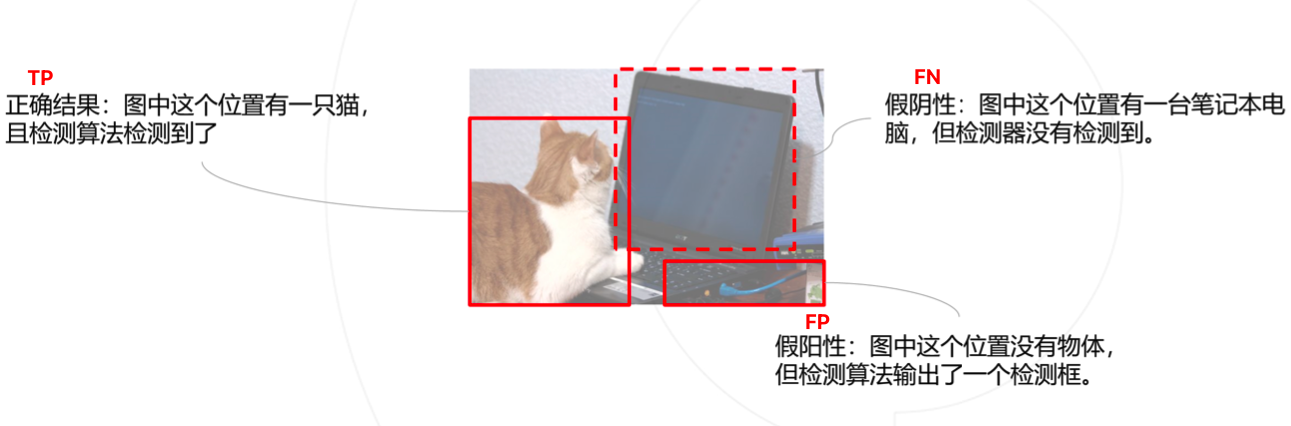
- 正确结果(True Positive):算法检测到了某类物体 (Positive),图中也确实有这个物体,检测结果正确(True)。(个人理解,这里其实成为正阳性更准确)
- 假阳性(False Positive):算法检测到了某类物体 (Positive),但图中其实没有这个物体,检测结果错误 (False)。通常我们把它也称为误检。
- 假阴性 (False Negative):算法没有检测到物体 (Negative),但图中其实有某类物体,检测结果错误(False)。通常,我们把它也称为漏检。
这里检测到的衡量标准:对于某个检测框,图中存在同类型的真值框且与之交并比大于阈值(通常取0.5)
例子:
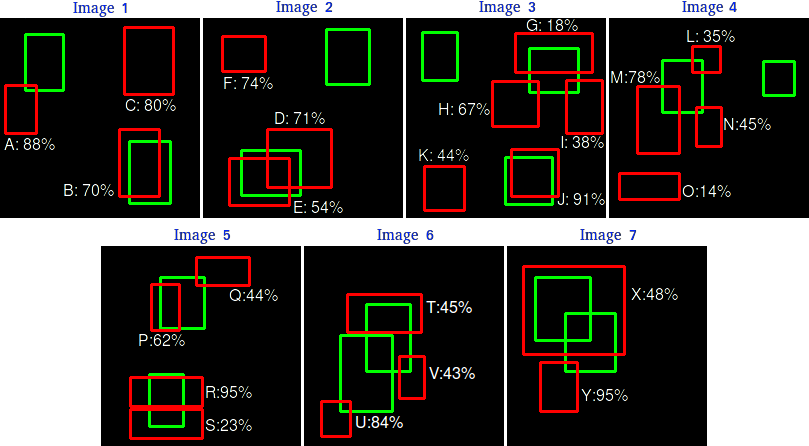 上面检测有 7 张图像,其中绿色边界框表示 15 个真值框,红色边界框表示 24 个检测框。每个检测到的对象都有一个置信度,并由一个字母 (A,B,…,Y) 标识。
上面检测有 7 张图像,其中绿色边界框表示 15 个真值框,红色边界框表示 24 个检测框。每个检测到的对象都有一个置信度,并由一个字母 (A,B,…,Y) 标识。
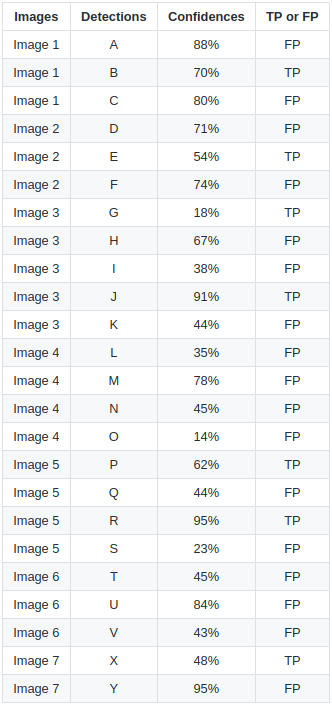
上表显示了边界框及其相应的置信度。最后一列将检测标识为 TP 或 FP。在这个例子中,如果 IOU 大于30% 则认为 TP,否则为 FP。通过查看上面的图像,我们可以大致判断检测是 TP 还是 FP
更具体的分析,可以参考 目标检测指标
目标检测评价指标
召回率、准确率

真值框总数与检测算法无关,因此只需将检测结果区分为TP和FP即可计算 recall 和 precision
两种极端情况:
- 检测器将所有锚框都判断为物体:召回率≈100%,但大量背景框预测为物体,FP很高,准确率很低;
- 检测器只输出确信度最高的1个检测框:以很大概率检测正确,准确率=100%,但因为大量物体被预测为背景,FN很高,召回率很低。
理想情况: 一个完美的检测器应该有100%召回率和100%的准确率;在算法能力有限的情况下,应该平衡二者。
通常做法: 将检测框按置信度排序,仅输出置信度大于某个阈值的若干个框。
AP(Average Precision)
为得到阈值无关的评分,可以遍历阈值,并对 Precision 和 Recall 求平均。
具体做法:
- 检测框按置信度排序,取前K个框计算 Precision 和 Recall。
- 遍历K从1至全部检测框,将得到的 Precision 和 Recall 值绘制在坐标系上,得到 PR 曲线。
- 定义 Average Precision = Precision 对 Recall 的平均值,即 PR 曲线下的面积,作为检测器的性能衡量指标。
笔者觉得这个指标很不科学!
原因是:一个好的检测器只需要在某个置信度阈值下能够检测出所有真实的目标,并且没有漏检和误检,那么就可以确定该检测器非常好,而不需要在其他置信度阈值下都表现好。
Mean AP
分类别统计AP,并按类别平均即得到 Mean AP。
部分数据集(如 COCO)还要求在不同的 loU (上面提到的IOU 大于30% )阈值下计算 Mean AP 并平均,作为最终评分;从0.5 ~ 0.05,每个0.05都会取一个IoU的阈值,计算 Mean AP,最终将这几个值进行平均,作为最终的一个评分。
可衡量检测器在不同定位精度要求下的性能。