阅读开源代码是提高写代码能力最好的方式之一,现在入坑机器学习领域,在众多框架中选择pytorch框架作为自己基本的深度学习框架,现在开始从最简单的pytorch代码部分阅读,学习下python技巧顺便深入学习下神经网络的代码实践。
关于阅读源码,我一开始在项目中调用pytorch模块和类,通过pycharm追踪源码,在pycharm中可以直接查看依赖包torch中源码,但是这样也不方便阅读torch源码,一个原因是pycharm中查看依赖包的源码内容,查看源码文件的方式是只读模式,没法在里面注释一些自己理解的东西,另一个原因是通过单步调试阅读代码是最容易理解代码的方式,想了想pytorch源码里面应该有对源码的测试代码可以直接跑起来,然后一步步运行,这样看着更方便。
从github上下载pytorch代码,通过CONTRIBUTING.md文件中指导编译源码,注意使用:python setup.py develop 以开发模式构建代码。这个过程在我的电脑上要跑将近两小时。。。忘了什么原因导致我跑了两次。。。四个小时没了(呜呜…)

先从加载和处理数据源码了解。
注:笔者阅读的pytorch版本为1.7.0,torchvision版本为0.6
Dataset 相关源码
MNIST类
类继承图:
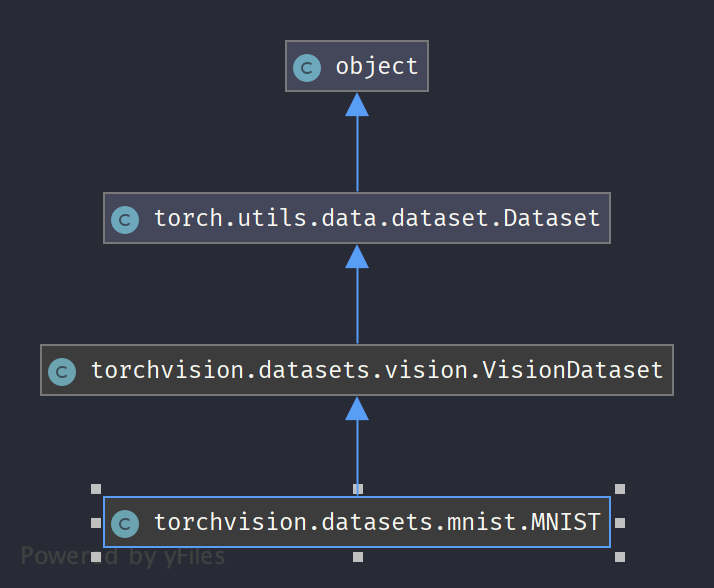
先来看看最常用的mnist数据集的使用,下面两行使用torchvision中提供的MNIST数据集类定义了两个数据集类,分别为训练数据集和测试数据集,那么为什么需要定义两个同样的数据集呢?其中一个因为是训练和测试使用的数据集不一样;另一个原因是训练和测试时候对应的batch_size大小不一样。下面进一步分析datasets.MNIST代码。
1
2
3
4
5
6
|
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
|
下面的代码来自torchvision.datasets.mnist模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
from .vision import VisionDataset
import warnings
from PIL import Image
import os
import os.path
import numpy as np
import torch
import codecs
import string
from .utils import download_url, download_and_extract_archive, extract_archive, \
verify_str_arg
class MNIST(VisionDataset):
resources = [
("http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz", "f68b3c2dcbeaaa9fbdd348bbdeb94873"),
("http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz", "d53e105ee54ea40749a09fcbcd1e9432"),
("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz", "9fb629c4189551a2d022fa330f9573f3"),
("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz", "ec29112dd5afa0611ce80d1b7f02629c")
]
training_file = 'training.pt'
test_file = 'test.pt'
classes = ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four',
'5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
@property
def train_labels(self):
warnings.warn("train_labels has been renamed targets")
return self.targets
@property
def test_labels(self):
warnings.warn("test_labels has been renamed targets")
return self.targets
@property
def train_data(self):
warnings.warn("train_data has been renamed data")
return self.data
@property
def test_data(self):
warnings.warn("test_data has been renamed data")
return self.data
|
类MNIST继承自VisionDataset,从名称可以知道VisionDataset是对流行的视觉数据集的抽象类,我从子类开始分析,后面再阅读分析VisionDataset类。MNIST类前面定义了四个属性,其中training_file、test_file保存将原始Minst数据处理之后的tensor格式的训练和测试数据的文件名。另外有四个方法分别是train_labels、test_labels、train_data、test_data,它们都被@property注解所修饰,@property这种注解装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改。那么我们就可以通过mnist.train_labels得到实例的私有属性,而实际上该过程调用的是train_labels()函数。上面部分除了@property其他的都很好理解了。下面来看这个类的其余部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
def __init__(self, root, train=True, transform=None, target_transform=None,
download=False):
super(MNIST, self).__init__(root, transform=transform,
target_transform=target_transform)
self.train = train # training set or test set
if download:
self.download()
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
data_file = self.training_file
else:
data_file = self.test_file
self.data, self.targets = torch.load(os.path.join(self.processed_folder, data_file))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], int(self.targets[index])
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.numpy(), mode='L') # @3
if self.transform is not None:
img = self.transform(img) # @1
if self.target_transform is not None:
target = self.target_transform(target) # @2
return img, target
def __len__(self):
return len(self.data)
|
__init__该类的构造器(constructor)函数入参transform和target_transform分别传入对数据图像和标签的预处理,在@1和@2处可以看到在每一张图像返回前分别对图像和标签进行用户自定义预处理。传入的train参数来决定该MNIST的dataset会返回训练集or测试集中的数据。
__getitem__根据python3中定义,如果在类中定义了__getitem__()方法,那么它的实例对象(假设为P)就可以以P[key]形式取值,当实例对象做P[key]运算时,就会调用类中的__getitem__()方法,这是一个很有意思也很有用的特性。具体到这个类的key为训练样本的idex为int类型代表第几个数据样本。在**@3**处将图像转成PIL图像对象,该PIL对象最终会通过transform预处理为tonsor对象。类MNIST剩余部分最主要就是下载download函数,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
@property
def raw_folder(self):
return os.path.join(self.root, self.__class__.__name__, 'raw')
@property
def processed_folder(self):
return os.path.join(self.root, self.__class__.__name__, 'processed')
@property
def class_to_idx(self):
return {_class: i for i, _class in enumerate(self.classes)}
def _check_exists(self):
return (os.path.exists(os.path.join(self.processed_folder,
self.training_file)) and
os.path.exists(os.path.join(self.processed_folder,
self.test_file)))
def download(self):
"""Download the MNIST data if it doesn't exist in processed_folder already."""
if self._check_exists(): # @4
return
os.makedirs(self.raw_folder, exist_ok=True)
os.makedirs(self.processed_folder, exist_ok=True)
# download files
for url, md5 in self.resources:
filename = url.rpartition('/')[2]
download_and_extract_archive(url, download_root=self.raw_folder, filename=filename, md5=md5)
# process and save as torch files
print('Processing...')
training_set = (
read_image_file(os.path.join(self.raw_folder, 'train-images-idx3-ubyte')),
read_label_file(os.path.join(self.raw_folder, 'train-labels-idx1-ubyte'))
)
test_set = (
read_image_file(os.path.join(self.raw_folder, 't10k-images-idx3-ubyte')),
read_label_file(os.path.join(self.raw_folder, 't10k-labels-idx1-ubyte'))
)
with open(os.path.join(self.processed_folder, self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.processed_folder, self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
def extra_repr(self):
return "Split: {}".format("Train" if self.train is True else "Test")
|
download函数下载原始mnist数据并将训练图像数据、训练标签数据存储在一个training_file文件中,将测试图像数据、测试标签数据存在test_file文件中,@4处可以看到当processed_folder目录下存在这两个文件,那么就不会通过网络下载,直接读取本地训练测试数据文件。另外,像download_and_extract_archive函数的具体实现,并没有在上面给出,这个就是更加细节的代码实现,此次代码阅读会忽略很多具体细节实现,专注于大的框架实现。
MNIST类继承自VisionDataset类,下面我们看看这个类中抽象出了哪些功能。
VisionDataset类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
class VisionDataset(data.Dataset):
_repr_indent = 4
def __init__(self, root, transforms=None, transform=None, target_transform=None):
if isinstance(root, torch._six.string_classes):
root = os.path.expanduser(root)
self.root = root
has_transforms = transforms is not None
has_separate_transform = transform is not None or target_transform is not None
if has_transforms and has_separate_transform:
raise ValueError("Only transforms or transform/target_transform can "
"be passed as argument")
# for backwards-compatibility @5
self.transform = transform
self.target_transform = target_transform
if has_separate_transform:
transforms = StandardTransform(transform, target_transform) # @6
self.transforms = transforms
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __repr__(self):
head = "Dataset " + self.__class__.__name__
body = ["Number of datapoints: {}".format(self.__len__())]
if self.root is not None:
body.append("Root location: {}".format(self.root))
body += self.extra_repr().splitlines()
if hasattr(self, "transforms") and self.transforms is not None:
body += [repr(self.transforms)]
lines = [head] + [" " * self._repr_indent + line for line in body]
return '\n'.join(lines)
def _format_transform_repr(self, transform, head):
lines = transform.__repr__().splitlines()
return (["{}{}".format(head, lines[0])] +
["{}{}".format(" " * len(head), line) for line in lines[1:]])
def extra_repr(self):
return ""
|
VisionDataset类中在**@5处注释向后兼容,可以看到在构造器(constructor)的入参有transforms、transform、target_transform三个预处理变量,那么哪一种是方式是重构后新引入的预处理方式呢?其实从@6**处就可以知道,为了兼容transform、target_transform传入方式,将它们两个构造为StandardTransform,也就是说重构后,希望用transforms(注意有个s)入参取代原有的方式。并且,机智的我(嘿嘿)通过查看该文件的修改历史,如下图,就可以看到源码作者的重构的意图。
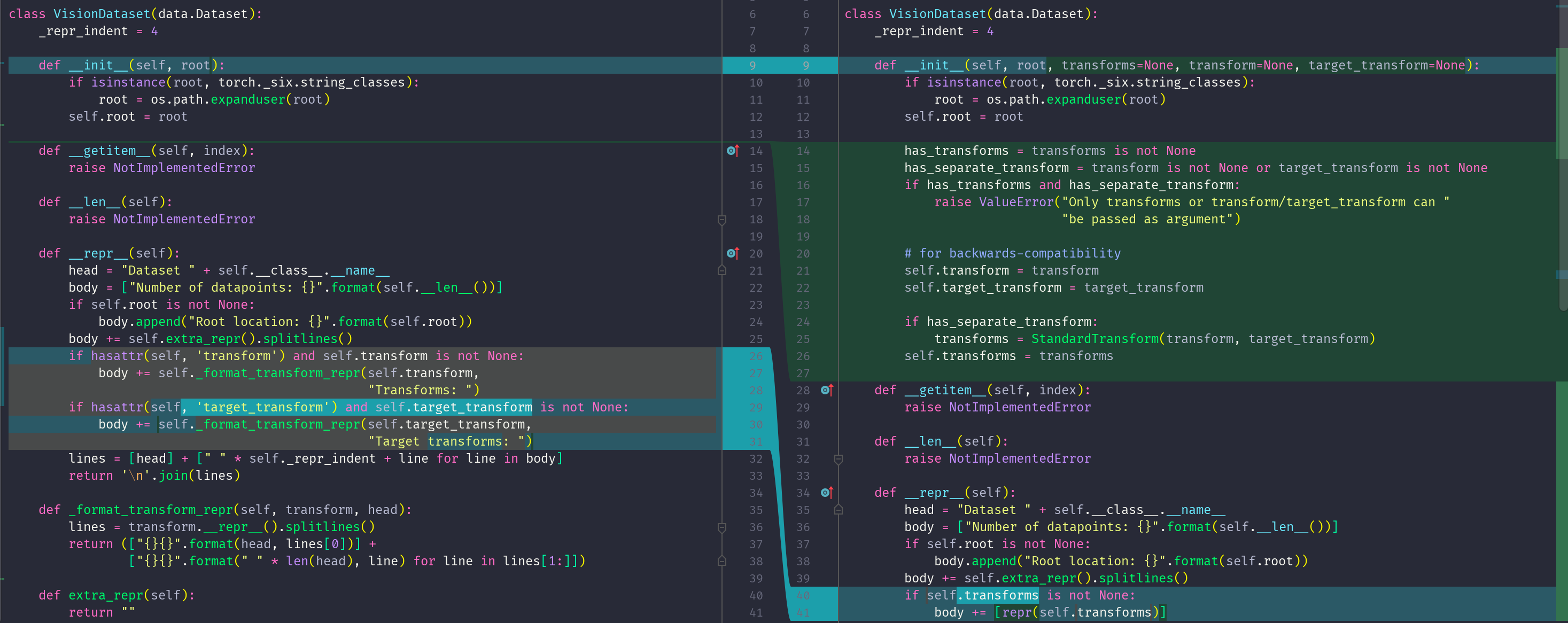
再来看看VisionDataset类中__repr__()的作用,简单理解就是,python中定义当输出print(instance)时,等同于执行print(instance.__repr__()),这样用户就可以通过实现自己的__repr__函数来控制我们想要的信息。默认情况下,__repr__() 会返回和调用者有关的 “类名+object at+内存地址”信息。另外,若调用repr(instance)也会执行__repr__()函数。
VisionDataset类继承自data.Dataset类,下面我们看看这个类中有哪些属性和方法。
Dataset
torch.utils.data.dataset模块中定义了几个数据类,是对pytorch搭建神经网络训练和测试所需要的数据集的封装和抽象。其中Dataset类是所有数据集类的父类,那么来看看这个类中定义了什么内容吧~
下面代码是我从pytorch源代码中拷贝过来的,省略了一些模块和类的导入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
T_co = TypeVar('T_co', covariant=True)
T = TypeVar('T')
class Dataset(Generic[T_co]):
r"""An abstract class representing a :class:`Dataset`.
All datasets that represent a map from keys to data samples should subclass
it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
data sample for a given key. Subclasses could also optionally overwrite
:meth:`__len__`, which is expected to return the size of the dataset by many
:class:`~torch.utils.data.Sampler` implementations and the default options
of :class:`~torch.utils.data.DataLoader`.
.. note::
:class:`~torch.utils.data.DataLoader` by default constructs a index
sampler that yields integral indices. To make it work with a map-style
dataset with non-integral indices/keys, a custom sampler must be provided.
"""
def __getitem__(self, index) -> T_co:
raise NotImplementedError
def __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]':
return ConcatDataset([self, other])
|
前两行定义两个用户自定义泛型,这种泛型编程自python3.5起开始引入到python中,有点类似于c++中泛型编程(不怎么用,忘得差不多了),c++中泛型会在编译器做类型检查和替换,属于强制类型检查,而在python中因为python类型都是弱类型,所以这种泛型编程更多的是给静态类型检测工具提供说明,帮助我们在代码编写阶段正确使用和传递python变量。目前,先忽略这些泛型类型。
在Dataset类中定义了两个基本函数,__getitem__实现key-value结构,__add__定义两个数据集叠加的操作。
下来我们来看看torchvision中其他的dataset。
类继承图:
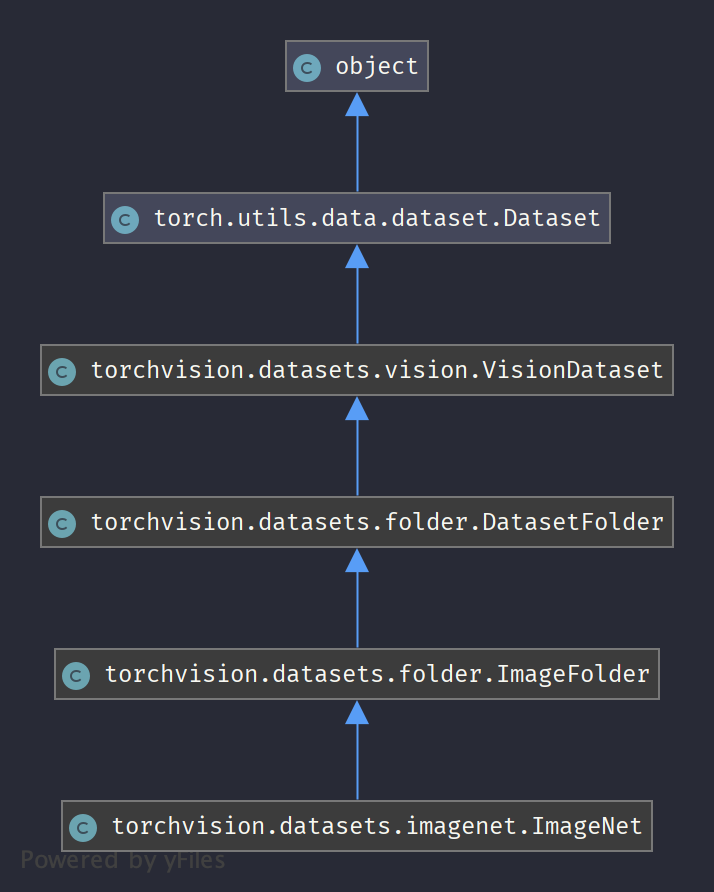
ImageFolder
下面源码摘抄自torchvision.datasets.folder模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
class ImageFolder(DatasetFolder):
"""A generic data loader where the images are arranged in this way: ::
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
Args:
root (string): Root directory path.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
loader (callable, optional): A function to load an image given its path.
is_valid_file (callable, optional): A function that takes path of an Image file
and check if the file is a valid file (used to check of corrupt files)
Attributes:
classes (list): List of the class names.
class_to_idx (dict): Dict with items (class_name, class_index).
imgs (list): List of (image path, class_index) tuples
"""
def __init__(self, root, transform=None, target_transform=None,
loader=default_loader, is_valid_file=None):
super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,
transform=transform,
target_transform=target_transform,
is_valid_file=is_valid_file)
self.imgs = self.samples
|
ImageFolder是一个通用的图像数据集类,它要求数据按照:
-
root/label01/xxx.png
-
root/label01/xxy.png
-
root/label01/xxz.png
-
root/label02/123.png
-
root/label02/nsdf3.png
-
root/label02/asd932_.png
的格式存放。这是分类数据集的数据和标签表示的另一种方式,通过目录名当作标签来存放图像数据,对于制作自定义数据集还是挺方便的。
ImageFolder继承自DatasetFolder,从名称就可以知道ImageFolder是类DatasetFolder的具体化,它只用来处理图像数据集,一般处理IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp') 中的图像格式。ImageFolder读取数据集后,得到三个属性:classes、class_to_idx、imgs。
Sampler 相关源码
源码位于 torch/utils/data/sampler.py,那么为什么要有Sampler相关类呢?我觉得可以这样理解:Dataset是为数据的总体,每次训练或者测试要从总体中随机或顺序抽取一个样本或者一批样本,那么不同的Sampler子类就表示从数据集中不同的抽取方式。
Sampler:所有Sampler的父类。SequentialSampler:顺序依次获取下标。RandomSampler:乱序获取下标。SubsetRandomSampler:某个子集内乱序获取下标。WeightedRandomSampler:为每个样本设置权重,权重大表示获取概率高。BatchSampler:即将若干个样本形成一个batch。
Sampler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
class Sampler(Generic[T_co]):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an :meth:`__iter__` method, providing a
way to iterate over indices of dataset elements, and a :meth:`__len__` method
that returns the length of the returned iterators.
.. note:: The :meth:`__len__` method isn't strictly required by
:class:`~torch.utils.data.DataLoader`, but is expected in any
calculation involving the length of a :class:`~torch.utils.data.DataLoader`.
"""
def __init__(self, data_source: Optional[Sized]) -> None:
pass
def __iter__(self) -> Iterator[T_co]:
raise NotImplementedError
# NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ]
#
# Many times we have an abstract class representing a collection/iterable of
# data, e.g., `torch.utils.data.Sampler`, with its subclasses optionally
# implementing a `__len__` method. In such cases, we must make sure to not
# provide a default implementation, because both straightforward default
# implementations have their issues:
#
# + `return NotImplemented`:
# Calling `len(subclass_instance)` raises:
# TypeError: 'NotImplementedType' object cannot be interpreted as an integer
#
# + `raise NotImplementedError()`:
# This prevents triggering some fallback behavior. E.g., the built-in
# `list(X)` tries to call `len(X)` first, and executes a different code
# path if the method is not found or `NotImplemented` is returned, while
# raising an `NotImplementedError` will propagate and and make the call
# fail where it could have use `__iter__` to complete the call.
#
# Thus, the only two sensible things to do are
#
# + **not** provide a default `__len__`.
#
# + raise a `TypeError` instead, which is what Python uses when users call
# a method that is not defined on an object.
# (@ssnl verifies that this works on at least Python 3.7.)
|
Sampler类是所有Sampler的父类,类中__init__该类的构造器(constructor)函数,__iter__提供迭代数据集元素索引的方法。
DataLoader相关源码
源码位于pytorch源码目录的torch/utils/data/dataloader.py,DataLoader类非常重要,它是我们作为深度学习模型训练与开发过程中直接用到的类,也就是说我们一般情况下,通过它来将我们的数据集数据加载到程序中,通常是用一个for循环遍历它,DataLoader类依赖Dataset类和Sampler类在内部为我们实现了很多数据集遍历的方式,方便于多种场景下使用。
分析DataLoader类之前,我先在之前学习pytorch的学习材料中,摘抄了一部分使用DataLoader的代码,先看看具体如何使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
# ... 省略部分代码
# 训练网络
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
|
上面代码是一个简单的训练过程,我们可以看到使用Dataset和DataLoader很方便地为模型训练提供数据加载、打乱、预处理、甚至是多进程加载。作为pytorch的使用者,准确详细的了解pytorch各种包,可以熟练快速开发我们自己的训练程序,下面先具体分析下DataLoader的接口。
源码比较长,我分析这样比较长的源码,将比较简单部分的代码解释直接写在源码里,作为注释;将复杂部分通过@符号标注,然后在源码后面部分分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
|
class DataLoader(Generic[T_co]):
r"""
原注释省略。
"""
dataset: Dataset[T_co]
batch_size: Optional[int]
num_workers: int
pin_memory: bool
drop_last: bool
timeout: float
sampler: Sampler
prefetch_factor: int
_iterator : Optional['_BaseDataLoaderIter']
__initialized = False
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Optional[Sampler[int]] = None,
batch_sampler: Optional[Sampler[Sequence[int]]] = None,
num_workers: int = 0, collate_fn: _collate_fn_t = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: _worker_init_fn_t = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
torch._C._log_api_usage_once("python.data_loader") # type: ignore
if num_workers < 0:
raise ValueError('num_workers option should be non-negative; '
'use num_workers=0 to disable multiprocessing.')
if timeout < 0:
raise ValueError('timeout option should be non-negative')
if num_workers == 0 and prefetch_factor != 2:
raise ValueError('prefetch_factor option could only be specified in multiprocessing.'
'let num_workers > 0 to enable multiprocessing.')
assert prefetch_factor > 0
if persistent_workers and num_workers == 0:
raise ValueError('persistent_workers option needs num_workers > 0')
self.dataset = dataset
self.num_workers = num_workers
self.prefetch_factor = prefetch_factor
self.pin_memory = pin_memory
self.timeout = timeout
self.worker_init_fn = worker_init_fn
self.multiprocessing_context = multiprocessing_context
# Arg-check dataset related before checking samplers because we want to
# tell users that iterable-style datasets are incompatible with custom
# samplers first, so that they don't learn that this combo doesn't work
# after spending time fixing the custom sampler errors.
if isinstance(dataset, IterableDataset):
self._dataset_kind = _DatasetKind.Iterable
# NOTE [ Custom Samplers and IterableDataset ]
#
# `IterableDataset` does not support custom `batch_sampler` or
# `sampler` since the key is irrelevant (unless we support
# generator-style dataset one day...).
#
# For `sampler`, we always create a dummy sampler. This is an
# infinite sampler even when the dataset may have an implemented
# finite `__len__` because in multi-process data loading, naive
# settings will return duplicated data (which may be desired), and
# thus using a sampler with length matching that of dataset will
# cause data lost (you may have duplicates of the first couple
# batches, but never see anything afterwards). Therefore,
# `Iterabledataset` always uses an infinite sampler, an instance of
# `_InfiniteConstantSampler` defined above.
#
# A custom `batch_sampler` essentially only controls the batch size.
# However, it is unclear how useful it would be since an iterable-style
# dataset can handle that within itself. Moreover, it is pointless
# in multi-process data loading as the assignment order of batches
# to workers is an implementation detail so users can not control
# how to batchify each worker's iterable. Thus, we disable this
# option. If this turns out to be useful in future, we can re-enable
# this, and support custom samplers that specify the assignments to
# specific workers.
if shuffle is not False:
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"shuffle option, but got shuffle={}".format(shuffle))
elif sampler is not None:
# See NOTE [ Custom Samplers and IterableDataset ]
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"sampler option, but got sampler={}".format(sampler))
elif batch_sampler is not None:
# See NOTE [ Custom Samplers and IterableDataset ]
raise ValueError(
"DataLoader with IterableDataset: expected unspecified "
"batch_sampler option, but got batch_sampler={}".format(batch_sampler))
else:
self._dataset_kind = _DatasetKind.Map
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
if batch_sampler is not None:
# auto_collation with custom batch_sampler
if batch_size != 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
batch_size = None
drop_last = False
elif batch_size is None:
# no auto_collation
if drop_last:
raise ValueError('batch_size=None option disables auto-batching '
'and is mutually exclusive with drop_last')
if sampler is None: # give default samplers
if self._dataset_kind == _DatasetKind.Iterable:
# See NOTE [ Custom Samplers and IterableDataset ]
sampler = _InfiniteConstantSampler()
else: # map-style
if shuffle:
# Cannot statically verify that dataset is Sized
# Somewhat related: see NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ]
sampler = RandomSampler(dataset, generator=generator) # type: ignore
else:
sampler = SequentialSampler(dataset)
if batch_size is not None and batch_sampler is None:
# auto_collation without custom batch_sampler
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.batch_size = batch_size
self.drop_last = drop_last
self.sampler = sampler
self.batch_sampler = batch_sampler
self.generator = generator
if collate_fn is None:
if self._auto_collation:
collate_fn = _utils.collate.default_collate
else:
collate_fn = _utils.collate.default_convert
self.collate_fn = collate_fn
self.persistent_workers = persistent_workers
self.__initialized = True
self._IterableDataset_len_called = None # See NOTE [ IterableDataset and __len__ ]
self._iterator = None
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
return _MultiProcessingDataLoaderIter(self)
@property
def multiprocessing_context(self):
return self.__multiprocessing_context
@multiprocessing_context.setter
def multiprocessing_context(self, multiprocessing_context):
if multiprocessing_context is not None:
if self.num_workers > 0:
if not multiprocessing._supports_context:
raise ValueError('multiprocessing_context relies on Python >= 3.4, with '
'support for different start methods')
if isinstance(multiprocessing_context, string_classes):
valid_start_methods = multiprocessing.get_all_start_methods()
if multiprocessing_context not in valid_start_methods:
raise ValueError(
('multiprocessing_context option '
'should specify a valid start method in {!r}, but got '
'multiprocessing_context={!r}').format(valid_start_methods, multiprocessing_context))
# error: Argument 1 to "get_context" has incompatible type "Union[str, bytes]"; expected "str" [arg-type]
multiprocessing_context = multiprocessing.get_context(multiprocessing_context) # type: ignore
if not isinstance(multiprocessing_context, python_multiprocessing.context.BaseContext):
raise TypeError(('multiprocessing_context option should be a valid context '
'object or a string specifying the start method, but got '
'multiprocessing_context={}').format(multiprocessing_context))
else:
raise ValueError(('multiprocessing_context can only be used with '
'multi-process loading (num_workers > 0), but got '
'num_workers={}').format(self.num_workers))
self.__multiprocessing_context = multiprocessing_context
def __setattr__(self, attr, val):
if self.__initialized and attr in (
'batch_size', 'batch_sampler', 'sampler', 'drop_last', 'dataset', 'persistent_workers'):
raise ValueError('{} attribute should not be set after {} is '
'initialized'.format(attr, self.__class__.__name__))
super(DataLoader, self).__setattr__(attr, val)
# We quote '_BaseDataLoaderIter' since it isn't defined yet and the definition can't be moved up
# since '_BaseDataLoaderIter' references 'DataLoader'.
def __iter__(self) -> '_BaseDataLoaderIter':
# When using a single worker the returned iterator should be
# created everytime to avoid reseting its state
# However, in the case of a multiple workers iterator
# the iterator is only created once in the lifetime of the
# DataLoader object so that workers can be reused
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
@property
def _auto_collation(self):
return self.batch_sampler is not None
@property
def _index_sampler(self):
# The actual sampler used for generating indices for `_DatasetFetcher`
# (see _utils/fetch.py) to read data at each time. This would be
# `.batch_sampler` if in auto-collation mode, and `.sampler` otherwise.
# We can't change `.sampler` and `.batch_sampler` attributes for BC
# reasons.
if self._auto_collation:
return self.batch_sampler
else:
return self.sampler
def __len__(self) -> int:
if self._dataset_kind == _DatasetKind.Iterable:
# NOTE [ IterableDataset and __len__ ]
#
# For `IterableDataset`, `__len__` could be inaccurate when one naively
# does multi-processing data loading, since the samples will be duplicated.
# However, no real use case should be actually using that behavior, so
# it should count as a user error. We should generally trust user
# code to do the proper thing (e.g., configure each replica differently
# in `__iter__`), and give us the correct `__len__` if they choose to
# implement it (this will still throw if the dataset does not implement
# a `__len__`).
#
# To provide a further warning, we track if `__len__` was called on the
# `DataLoader`, save the returned value in `self._len_called`, and warn
# if the iterator ends up yielding more than this number of samples.
# Cannot statically verify that dataset is Sized
length = self._IterableDataset_len_called = len(self.dataset) # type: ignore
if self.batch_size is not None: # IterableDataset doesn't allow custom sampler or batch_sampler
from math import ceil
if self.drop_last:
length = length // self.batch_size
else:
length = ceil(length / self.batch_size)
return length
else:
return len(self._index_sampler)
|