前言
OpenMMLab学习资料:OpenMMLab 模块化设计背后的功臣
对于mmdetection的学习,可以直接阅读官方的文档,现在官方提供了中文文档,非常详细,点击mmdetection中文文档阅读。
关于基于mmdetection框架实现Faster R-CNN算法,可以先阅读官方在知乎上发布的文章,轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN,本篇博客是对其进行从源码实现层面进行补充解读。
mmdetection代码框架
通过下面命令拉取最新的代码
| |
代码仓库主分支为master分支,目前计算机视觉领域中目标检测算法正在快速发展,mmdetection也不断地实现新的算法,最新实现的算法查看CHANGELOG。
如果觉得master代码更新比较频繁,影响自己基于mmdetection的算法实现,也可以基于最新发布的版本创建自己的分支,如下命令:
| |
目前还是推荐直接使用master代码,并且要经常 git pull 拉取最新的代码,这样最新的一些组件也会更新,方便基于最新的组件搭建自己的网络算法。
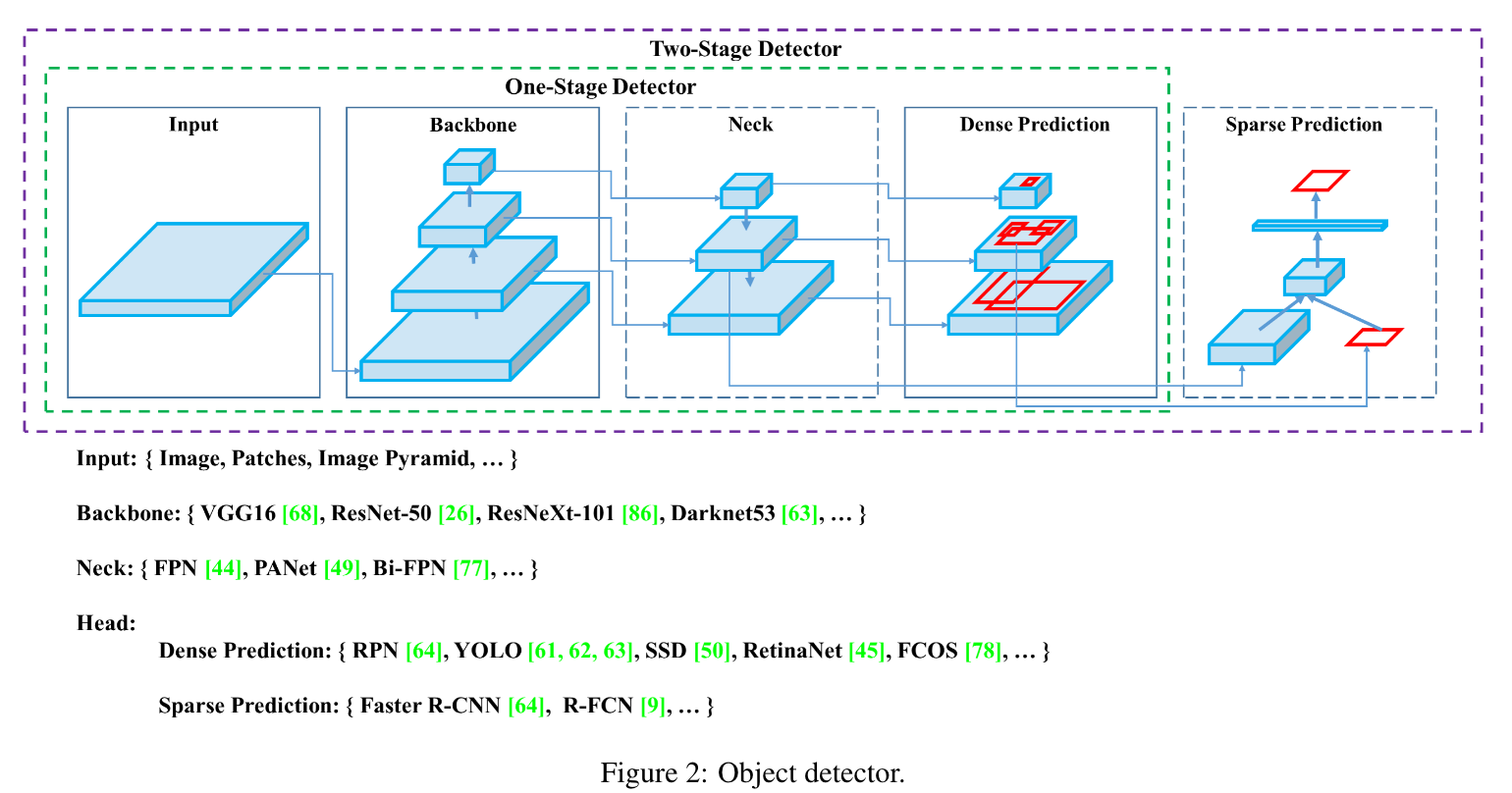
之前阅读的YOLO v4论文中,作者将目标检测抽象为下面几个部分,mmdetection的代码也是这样抽象的:
下面代码分析基于mmdetection的源码当前最近commit: ca11860f4f3c3ca2ce8340e2686eeaec05b29111 ,时间 2022.06.20。
下面是mmdetection代码框架的结构:
| |
以下是configs目录下的配置文件说明:
| |
以下是mmdet(核心代码)目录下的代码说明:
| |
以下是tools目录下的代码说明:
| |
Faster R-CNN 模型训练
| |
根据官方文档,配置相关环境,下载VOC数据集(这里选择相对较小的VOC数据进行训练),并且组织好数据集目录结构,如上所示,然后就可以使用下面命令进行训练:
| |
笔者训练得到的结果是:mAP 78.8,该结果和官方给的代码结果差将近两个点,可能是训练时候的参数设置不一样导致的。
Faster R-CNN 模型测试
使用下面命令进行测试:
| |
这里的checkpoints目录下的模型文件是我下载mmdetection训练好的模型文件,可以替换成自己训练好的文件,进行测试。
Faster R-CNN 配置文件解读
上面训练和测试使用的模型配置文件都是configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py,内容如下:
| |
可以看到上面的配置文件,继承自三个配置文件,下面解读configs/_base_/models/faster_rcnn_r50_fpn.py模型配置文件,内容如下:
| |
下面对configs/_base_/datasets/voc0712.py数据集配置文件进行解读,其内容如下:
| |
笔者在源码基础上做了一些修改,将samples_per_gpu修改为8,workers_per_gpu修改为8,lr_config修改为dict(policy='step', step=[8, 11]),runner修改为dict(type='EpochBasedRunner', max_epochs=12),注意实际训练时候batch_size为samples_per_gpu x gpus,我这里训练时候只用了一个GPU,所以batch_size为 8。
训练代码解读
首先从tools里面的train.py入手,官方源码文件train.py。
该python文件中main函数其实就做了四件事,这也是训练神经网络通用的步骤:
- 设定和读取各种配置;
- 创建模型;
- 创建数据集;
- 将模型,数据集和配置传进训练函数,进行训练;
下面截取tools/train.py中main函数的代码片段进行解读,其内容如下:
| |
让我们继续阅读build_detector函数的代码片段,其内容如下,该代码在mmdect/models/builder.py中:
| |
这里采用了Registry方式,即在mmdet/models/builder.py中实例化了一个Registry对象,该对象的父类是MMCV_MODELS,该类是mmcv中的一个类,其作用是用来管理多个模型,其中有一个build函数,该函数的作用是根据模型的配置信息,创建模型,并返回模型对象。
下面代码来自mmcv,版本为1.5.2。
从上面代码可以看到,mmdet中创建模型的函数build_model_from_cfg继承自mmcv/cnn/builder.py中的build_model_from_cfg函数,其内容如下:
| |
下面我们在mmcv/utils/registry.py中查看build_from_cfg代码,如下:
| |
mmcv源码查看,到此为止。
本篇博客分析Faster R-CNN,该算法在mmdet中模型注册type为FasterRCNN,我们找到该类的实现,位置为mmdet/models/detectors/faster_rcnn.py,如下:
| |
那么核心功能肯定都在TwoStageDetector里了。看代码之前首先回顾一下一个经典的双阶段检测Faster R-CNN的流程。
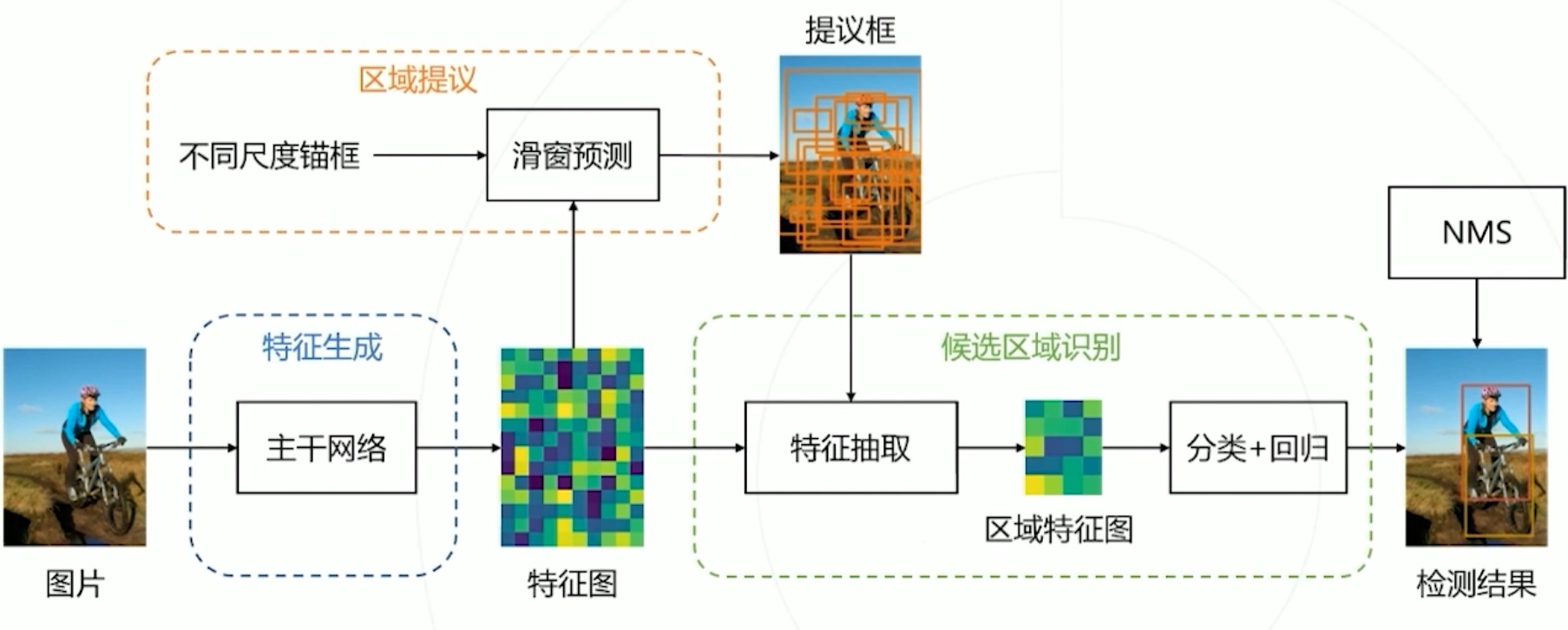
下面我们来分析下/mmdet/models/detectors/two_stage.py文件,如下:
| |
关于上面代码,我画了一个示意图,可以方便理解两阶段检测的架构。
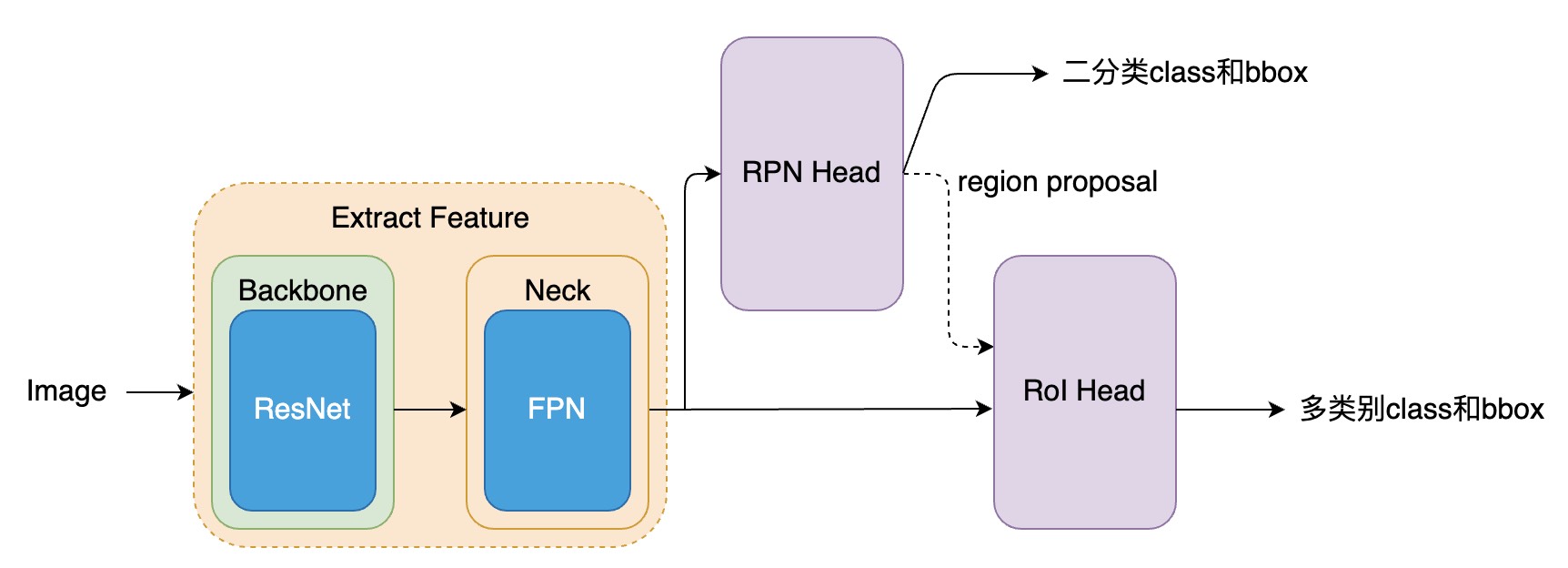
可以看到 TwoStageDetector 类的 forward_train 函数比较简单,最难的部分为两个 head ,分别为 RPNHead 和 StandardRoIHead,下面先分析 RPNHead。
该代码位于mmdet/models/dense_heads/rpn_head.py。