前言
谁适合阅读这篇文章?
- 具备 C++ 基础:对线程池和网络编程有一定了解,希望进一步深入相关技术。
- 热衷于 C++14 的应用:对现代 C++ 特性感兴趣,并追求更高的代码性能和效率。
- 对 Web 服务器实现感兴趣:想要理解 Web 服务器的核心原理和实现细节,从源码到原理全方位掌握。
如何更好地阅读本篇文章?
针对希望通过本篇文章了解 WebServer 实现原理的读者:
建议使用 Snipaste 等贴图工具,将代码片段或原理示意图固定在电脑屏幕的显眼位置。这样在阅读源码解析时,可以随时对照代码或参考原理图,帮助更直观地理解 WebServer 的设计思路和实现细节。
针对希望深入研究源码并亲自动手实践的读者:
强烈推荐使用 VS Code 等现代化 IDE,并确保安装支持 C++14 的编译器。参考GDB 调试秘籍:像高手一样排查问题,通过逐步调试代码的方式,深入分析其运行过程。这样的实践方法不仅能加深对源码的理解,还能有效提升调试技能和对程序逻辑的掌控能力。
项目简介
该项目是用 C++14 实现的高性能WEB服务器,经过 webbenchh 压力测试可以实现上万的QPS,通过该项目达到以下目的:
- 阅读源码提升自己编程水平;
- 进一步理解 HTTP 协议;
- 熟悉 C++14 相关工具;
- 熟悉线程池;
- 理解 IO 复用技术 Epoll;
- 熟悉定时器的设计与实现;
- 熟悉异步日志系统的设计;
项目目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| .
├── code 源代码
│ ├── buffer
│ ├── config
│ ├── http
│ ├── log
│ ├── timer
│ ├── pool
│ ├── server
│ └── main.cpp
├── test 单元测试
│ ├── Makefile
│ └── test.cpp
├── resources 静态资源
│ ├── index.html
│ ├── image
│ ├── video
│ ├── js
│ └── css
├── bin 可执行文件
│ └── server
├── log 日志文件
├── webbench-1.5 压力测试
├── build
│ └── Makefile
├── Makefile
├── LICENSE
└── readme.md
|
项目启动
配置数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 建立yourdb库
create database webserver;
// 创建user表
USE webserver;
CREATE TABLE user(
username char(50) NULL,
password char(50) NULL
)ENGINE=InnoDB;
// 添加数据
INSERT INTO user(username, password) VALUES('zhangsan', '123456');
INSERT INTO user(username, password) VALUES('lisi', '123456');
|
数据库中数据如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| mysql> USE webserver;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SHOW tables;
+---------------------+
| Tables_in_webserver |
+---------------------+
| user |
+---------------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM user;
+----------+----------+
| username | password |
+----------+----------+
| zhangsan | 123456 |
| lisi | 123456 |
+----------+----------+
2 rows in set (0.00 sec)
|
编译运行
压力测试
1
2
3
4
| ./webbench-1.5/webbench -c 100 -t 10 http://ip:port/
./webbench-1.5/webbench -c 1000 -t 10 http://ip:port/
./webbench-1.5/webbench -c 5000 -t 10 http://ip:port/
./webbench-1.5/webbench -c 10000 -t 10 http://ip:port/
|
测试结果如下:

功能介绍
- 利用IO复用技术Epoll与线程池实现多线程的Reactor高并发模型;
- 利用正则与状态机解析HTTP请求报文,实现处理静态资源的请求;
- 利用标准库容器封装char,实现自动增长的缓冲区;
- 基于小根堆实现的定时器,关闭超时的非活动连接;
- 利用单例模式与阻塞队列实现异步的日志系统,记录服务器运行状态;
- 利用RAII机制实现了数据库连接池,减少数据库连接建立与关闭的开销,同时实现了用户注册登录功能。
时序图
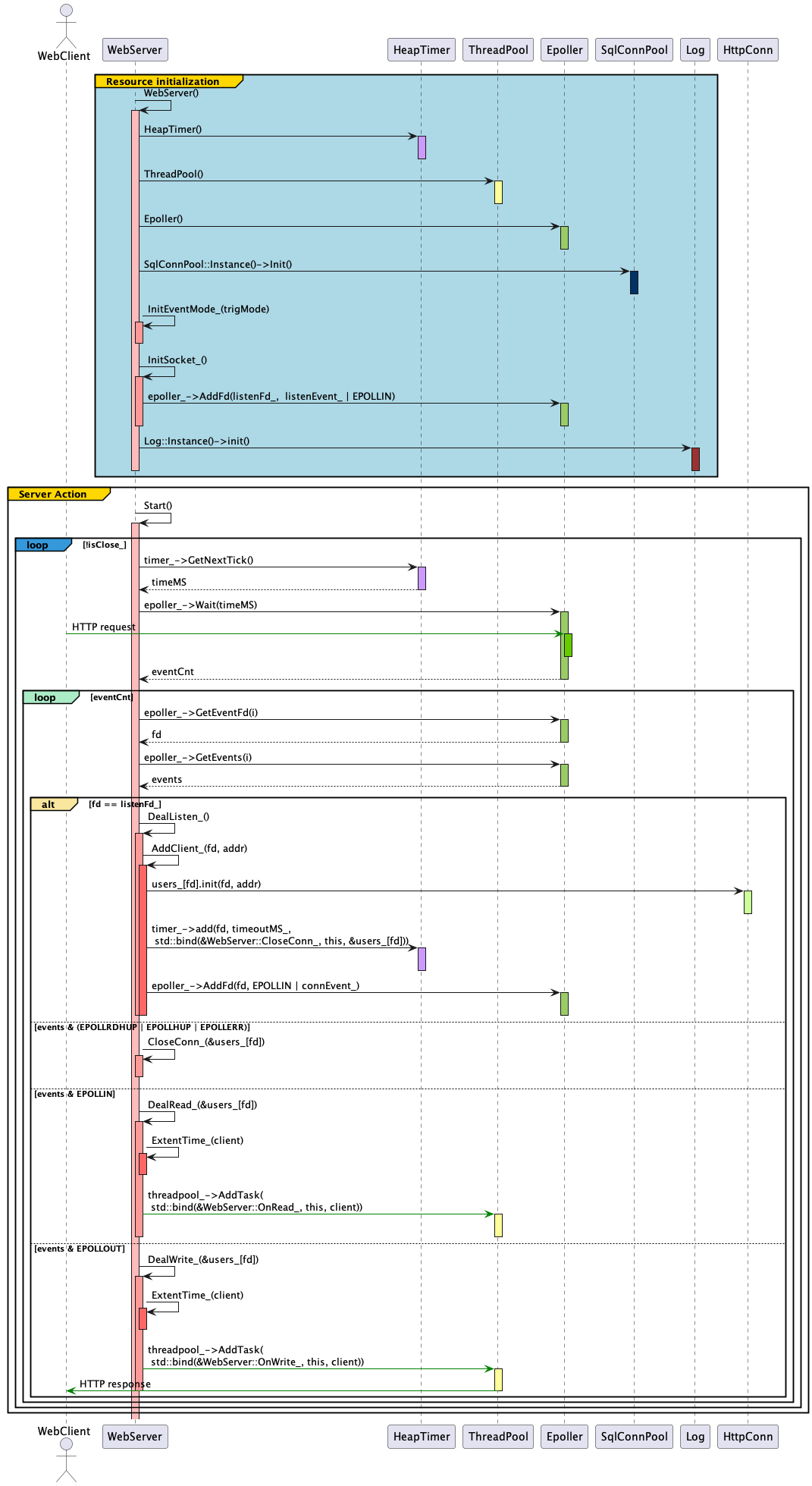
上面时序图展示了 WebServer 从服务启动时进行资源初始化、客户端发送一个 HTTP 请求到 WebServer 服务器、监听套接字的 Epoller 接受到 TCP 连接请求并进行分发的过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
| #include <unistd.h>
#include "server/webserver.h"
int main() {
/* 守护进程 后台运行 */
//daemon(1, 0);
WebServer server(
1316, 3, 60000, false, /* 端口 ET模式 timeoutMs 优雅退出 */
3306, "root", "123456", "webserver", /* Mysql配置 */
12, 6, true, 1, 1024); /* 连接池数量 线程池数量 日志开关 日志等级 日志异步队列容量 */
server.Start();
}
|
上面代码为 WebServer 服务器实例化时资源加载和实例启动源码,该阶段完成上面时序图 Resource initialization 框标的过程。
编译运行后,当我们启动时,首先通过上面代码启动服务,这时一个 HTTP 服务器开始对外服务,我们可以在游览器中访问地址:http://127.0.0.1:1316 ,打开如下界面。
通过游览器访问时,这里游览器给服务器发送了一个处于应用层 HTTP 协议的 GET 请求,上面时序图绿色箭头代表客户端用户主动发起请求路径为 / 的请求,该请求会被 Linux 内核提供给应用程序的同时监听多个文件描述符的事件通知机制 epoll 响应,那么为什么 epoll 会处理这样的网络请求呢?
在 Resource initialization 资源初始化阶段,就在 WebServer::InitSocket_() 函数中通过 socket 传输层编程设置一个绑定到协议为 TCP 且端口为 1316 上的网络监听套接字 listenFd_ ,通过调用 listen(listenFd_, 6) 该监听套接字一直处于监听状态;而且,通过 epoller_->AddFd(listenFd_, listenEvent_ | EPOLLIN) 调用,将该套接字添加到多路复用机制 epoll 的注册事件中,该过程的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| bool WebServer::InitSocket_() {
int ret;
struct sockaddr_in addr;
if(port_ > 65535 || port_ < 1024) {
LOG_ERROR("Port:%d error!", port_);
return false;
}
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port_);
struct linger optLinger = { 0 };
if(openLinger_) {
/* 优雅关闭: 直到所剩数据发送完毕或超时 */
optLinger.l_onoff = 1;
optLinger.l_linger = 1;
}
listenFd_ = socket(AF_INET, SOCK_STREAM, 0);
if(listenFd_ < 0) {
LOG_ERROR("Create socket error!", port_);
return false;
}
ret = setsockopt(listenFd_, SOL_SOCKET, SO_LINGER, &optLinger, sizeof(optLinger));
if(ret < 0) {
close(listenFd_);
LOG_ERROR("Init linger error!", port_);
return false;
}
int optval = 1;
/* 端口复用 */
/* 只有最后一个套接字会正常接收数据。 */
ret = setsockopt(listenFd_, SOL_SOCKET, SO_REUSEADDR, (const void*)&optval, sizeof(int));
if(ret == -1) {
LOG_ERROR("set socket setsockopt error !");
close(listenFd_);
return false;
}
ret = bind(listenFd_, (struct sockaddr *)&addr, sizeof(addr));
if(ret < 0) {
LOG_ERROR("Bind Port:%d error!", port_);
close(listenFd_);
return false;
}
ret = listen(listenFd_, 6);
if(ret < 0) {
LOG_ERROR("Listen port:%d error!", port_);
close(listenFd_);
return false;
}
ret = epoller_->AddFd(listenFd_, listenEvent_ | EPOLLIN);
if(ret == 0) {
LOG_ERROR("Add listen error!");
close(listenFd_);
return false;
}
SetFdNonblock(listenFd_);
LOG_INFO("Server port:%d", port_);
return true;
}
|
接着上面,用户发起请求,此时,Linux 内核唤醒起工作在设置了超时阻塞的 epoller_->Wait(timeMS) ,并且返回事件个数。这里,我们看到设置了超时阻塞等待,因为可能达到超时时间,没有任何事件发生,此时,通过外层 while 循环进入到下一轮循环中,并且当获取最小设置的超时间,继续在 epoller_ 上等待事件发生。该过程如下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| void WebServer::Start() {
int timeMS = -1; /* epoll wait timeout == -1 无事件将阻塞 */
if(!isClose_) { LOG_INFO("========== Server start =========="); }
while(!isClose_) {
if(timeoutMS_ > 0) {
timeMS = timer_->GetNextTick();
}
int eventCnt = epoller_->Wait(timeMS);
for(int i = 0; i < eventCnt; i++) {
/* 处理事件 */
int fd = epoller_->GetEventFd(i);
uint32_t events = epoller_->GetEvents(i);
if(fd == listenFd_) {
DealListen_();
}
else if(events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)) {
assert(users_.count(fd) > 0);
CloseConn_(&users_[fd]);
}
else if(events & EPOLLIN) {
assert(users_.count(fd) > 0);
DealRead_(&users_[fd]);
}
else if(events & EPOLLOUT) {
assert(users_.count(fd) > 0);
DealWrite_(&users_[fd]);
} else {
LOG_ERROR("Unexpected event");
}
}
}
}
|
拿到事件个数,通过循环遍历事件,进行处理事件。这里,通过 int fd = epoller_->GetEventFd(i); uint32_t events = epoller_->GetEvents(i); 代码获取具体事件发生哪个文件描述符上和对应的事件类型。具体参考:[[Linux 服务器编程-IO模式]]
在这里,我们可以通过工具 gdb 进行调试,通过断点来观察当发起请求时的事件类型。运行下面命令:
1
| $ gdb ./bin/server # 进入调试
|
在这里,采用条件断点,当有具体事件返回时,才暂停运行,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Type "apropos word" to search for commands related to "word"...
Reading symbols from ./bin/server...
(gdb) b code/server/webserver.cpp:85 if eventCnt > 0
Breakpoint 1 at 0x5123e: file ../code/server/webserver.cpp, line 85.
(gdb) r
Starting program: /home/andy/Workplace/cpp_advance/cpp14/WebServer/bin/server
warning: Error disabling address space randomization: Operation not permitted
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7f62a5409640 (LWP 2889)]
[New Thread 0x7f62a4c08640 (LWP 2890)]
[New Thread 0x7f62a4407640 (LWP 2891)]
[New Thread 0x7f62a3c06640 (LWP 2892)]
[New Thread 0x7f62a3405640 (LWP 2893)]
[New Thread 0x7f62a2c04640 (LWP 2894)]
[New Thread 0x7f62a2403640 (LWP 2895)]
|
此时,我们刷新游览器,重新发起请求,如下,可以看到成功返回在 socket 监听套接字上的事件,事件类型为 EPOLLIN,表示对应的文件描述符可以读。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Thread 1 "server" hit Breakpoint 1, WebServer::Start (this=0x7ffd64d41970) at ../code/server/webserver.cpp:85
85 for(int i = 0; i < eventCnt; i++) {
(gdb) p eventCnt
$1 = 1
(gdb) n
87 int fd = epoller_->GetEventFd(i);
(gdb) n
88 uint32_t events = epoller_->GetEvents(i);
(gdb) n
89 if(fd == listenFd_) {
(gdb) n
90 DealListen_();
(gdb) p events & EPOLLIN
$2 = 1
|
下面代码我们来看看当第一次发起请求时,客户端是如何与服务端建立并保持一个计时连接,并且如何处理一个 HTTP 的资源请求的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| void WebServer::AddClient_(int fd, sockaddr_in addr) {
assert(fd > 0);
users_[fd].init(fd, addr);
if(timeoutMS_ > 0) {
timer_->add(fd, timeoutMS_, std::bind(&WebServer::CloseConn_, this, &users_[fd]));
}
epoller_->AddFd(fd, EPOLLIN | connEvent_);
SetFdNonblock(fd);
LOG_INFO("Client[%d] in!", users_[fd].GetFd());
}
void WebServer::DealListen_() {
struct sockaddr_in addr;
socklen_t len = sizeof(addr);
do {
int fd = accept(listenFd_, (struct sockaddr *)&addr, &len);
if(fd <= 0) { return;}
else if(HttpConn::userCount >= MAX_FD) {
SendError_(fd, "Server busy!");
LOG_WARN("Clients is full!");
return;
}
AddClient_(fd, addr);
} while(listenEvent_ & EPOLLET);
}
|
上面代码可以看到,当客户端与服务端建立连接后,会通过 accept(listenFd_, (struct sockaddr *)&addr, &len) 在服务端返回一个新的 socket 套接字,即文件描述符 fd,此时,在传输层上已经建立了 TCP 稳定连接;之后服务端生成一个表示连接的对象 HttpConn ,存入 users_ 字典中;表示一个连接对象的 HttpConn 中,保存了上面新的套接字 fd_、客户端地址 addr_以及该连接的状态 isClose_;之后,通过 epoller_->AddFd(fd, EPOLLIN | connEvent_) 将这个新的套接字也加入到 epoll 事件监听中,WebServer::DealListen_() 在没有其他客户端试图建立连接时,通过语句 if(fd <= 0) { return;} 返回到 WebServer::Start() 函数的外层循环中。此时,客户端因为首次发起连接,服务端成功与客户端建立连接,并且监听相应的新的网络套接字。
由于首次发起连接时,客户端向服务端发送数据包,该数据包还未被读取,此时,新的 socket 套接字 fd 处于可读状态 EPOLLIN,因此在 WebServer::Start() 函数的外层循环 while(!isClose_) 执行到 int eventCnt = epoller_->Wait(timeMS) 语句时,会立即返回事件数,如果没有其他客户端发起连接,那么只有刚才成功建立连接的客户端,那么此时,事件数为 1,并且该事件发生在建立 TCP 连接的套接字 fd 上且事件为 EPOLLIN,此时,调用 DealRead_(&users_[fd]) 处理该请求并且处理 HTTP 协议的信息后,构造客户端请求对应的 HTTP 资源,并且通过 epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLOUT) 使得 epoll 机制在套接字 fd 上同时监听是否可写的状态。下面代码展示了该过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| void WebServer::DealRead_(HttpConn* client) {
assert(client);
ExtentTime_(client);
threadpool_->AddTask(std::bind(&WebServer::OnRead_, this, client));
}
void WebServer::OnRead_(HttpConn* client) {
assert(client);
int ret = -1;
int readErrno = 0;
ret = client->read(&readErrno);
if(ret <= 0 && readErrno != EAGAIN) {
CloseConn_(client);
return;
}
OnProcess(client);
}
void WebServer::OnProcess(HttpConn* client) {
if(client->process()) {
epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLOUT);
} else {
epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLIN);
}
}
bool HttpConn::process() {
request_.Init();
if(readBuff_.ReadableBytes() <= 0) {
return false;
}
else if(request_.parse(readBuff_)) {
LOG_DEBUG("%s", request_.path().c_str());
response_.Init(srcDir, request_.path(), request_.IsKeepAlive(), 200);
} else {
response_.Init(srcDir, request_.path(), false, 400);
}
response_.MakeResponse(writeBuff_);
/* 响应头 */
iov_[0].iov_base = const_cast<char*>(writeBuff_.Peek());
iov_[0].iov_len = writeBuff_.ReadableBytes();
iovCnt_ = 1;
/* 文件 */
if(response_.FileLen() > 0 && response_.File()) {
iov_[1].iov_base = response_.File();
iov_[1].iov_len = response_.FileLen();
iovCnt_ = 2;
}
LOG_DEBUG("filesize:%d, %d to %d", response_.FileLen() , iovCnt_, ToWriteBytes());
return true;
}
|
与上面情况类似,当 DealRead_(&users_[fd]) 执行结束后,并且结束内层循环后,下一轮外层外层循环 while(!isClose_) 执行到 int eventCnt = epoller_->Wait(timeMS) 语句时,会立即返回事件数,此时,如果没有其他客户端发起连接,只有刚才成功建立连接的客户端,那么此时,事件数为 1,并且该事件发生在建立 TCP 连接的套接字 fd 上且事件为 EPOLLOUT,此时,执行调用 DealWrite_(&users_[fd]) 将上面构建的构造客户端请求对应的 HTTP 资源,即 HttpConn 中的 response_ 内容发送给客户端。下面代码展示了该过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| void WebServer::DealWrite_(HttpConn* client) {
assert(client);
ExtentTime_(client);
threadpool_->AddTask(std::bind(&WebServer::OnWrite_, this, client));
}
void WebServer::OnWrite_(HttpConn* client) {
assert(client);
int ret = -1;
int writeErrno = 0;
ret = client->write(&writeErrno);
if(client->ToWriteBytes() == 0) {
/* 传输完成 */
if(client->IsKeepAlive()) {
OnProcess(client);
return;
}
}
else if(ret < 0) {
if(writeErrno == EAGAIN) {
/* 继续传输 */
epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLOUT);
return;
}
}
CloseConn_(client);
}
|
关键技术
IO复用技术 Epoll
具体参考 [[Linux 服务器编程-IO模式#epoll]]
线程池
简介
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
而本文描述的是一种简单的线程池实现方案,更复杂的线程池实现方法,请参考下面的资料学习。
参考资料
代码解析
为了方便理解代码,在这里我先通过下面示意图,简单描述该版本的线程池大概机制。
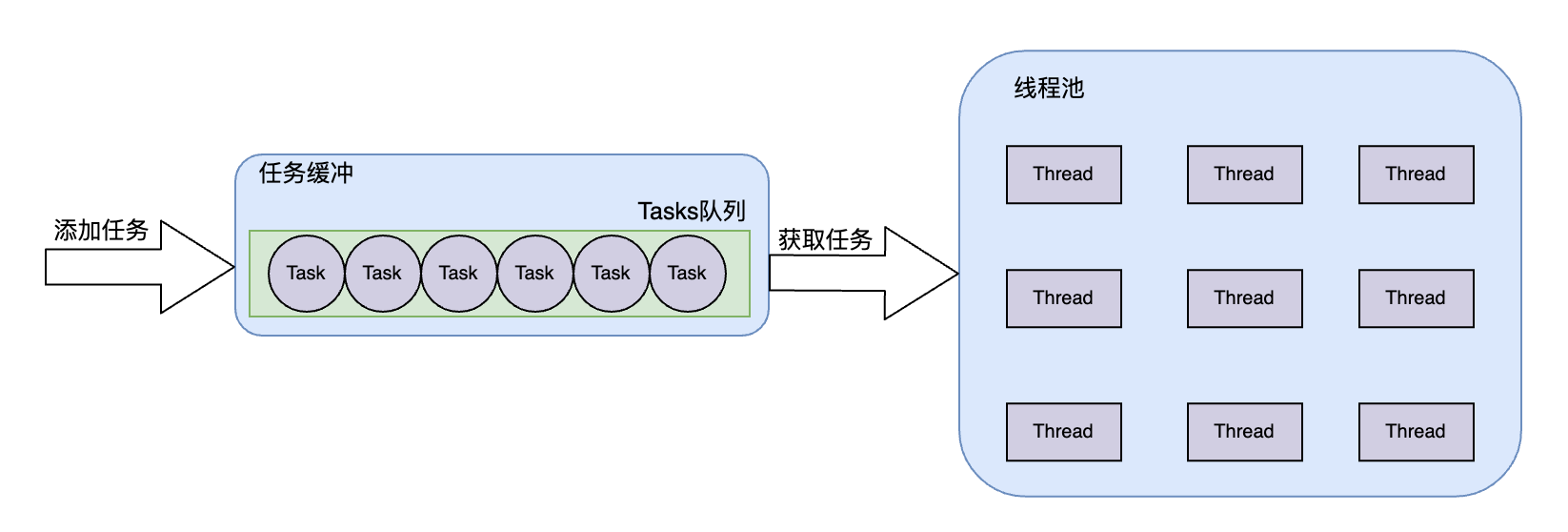
下面代码实现了一个如上图线程池,整个线程池是个生产者消费者模型,该线程池一开始创建 threadCount 个固定线程,这些线程作为消费者,当线程被唤醒时,从任务队列中获取任务,执行任务;而生产者通过 AddTask(F&& task) 方法将生产的任务添加到任务缓冲队列中。可以看到,整个TaskQueue 任务队列作为临界资源被多个线程异步访问,为了保障多个线程能够安全访问 TaskQueue 中 std::queue<std::function<void()>> tasks 队列 变量时,每次操作都需要通过互斥量 std::mutex mtx 进行加锁后再进行访问。
注:这里笔者将源码中 Pool 结构体改名成 TaskQueue,代表的含义更为合适。
可以先阅读下面源码,后面给出源码相关问题及回答。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| /*
* @File : threadpool.h
* @Author : mark
* @Date : 2020-06-15
* @copyleft Apache 2.0
*/
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <mutex>
#include <condition_variable>
#include <queue>
#include <thread>
#include <functional>
class ThreadPool {
public:
explicit ThreadPool(size_t threadCount = 8): task_queue_(std::make_shared<TaskQueue>()) {
assert(threadCount > 0);
for(size_t i = 0; i < threadCount; i++) {
std::thread([task_queue = task_queue_] {
std::unique_lock<std::mutex> locker(task_queue->mtx);
while(true) {
if(!task_queue->tasks.empty()) {
auto task = std::move(task_queue->tasks.front());
task_queue->tasks.pop();
locker.unlock();
task();
locker.lock();
}
else if(task_queue->isClosed) break;
else task_queue->cond.wait(locker);
}
}).detach();
}
}
ThreadPool() = default;
ThreadPool(ThreadPool&&) = default;
~ThreadPool() {
if(static_cast<bool>(task_queue_)) {
{
std::lock_guard<std::mutex> locker(task_queue_->mtx);
task_queue_->isClosed = true;
}
task_queue_->cond.notify_all();
}
}
template<class F>
void AddTask(F&& task) {
{
std::lock_guard<std::mutex> locker(task_queue_->mtx);
task_queue_->tasks.emplace(std::forward<F>(task));
}
task_queue_->cond.notify_one();
}
private:
struct TaskQueue {
std::mutex mtx;
std::condition_variable cond;
bool isClosed;
std::queue<std::function<void()>> tasks;
};
std::shared_ptr<TaskQueue> task_queue_;
};
#endif //THREADPOOL_H
|
为什么该线程池所有的实现在 threadpool.h 中完成?
上面源码为线程池的头文件 threadpool.h,而且该线程池没有对应的 threadpool.cpp 实现代码文件,这种在类中实现方法的方式,使得类中方法都是缺省内联的,这样在编译的时候把函数调用的部分直接换成函数代码,而不是进行函数调用,这适用于函数代码少的时候,可以避免调用带来栈空间的消耗,也可以减少一定的调用时间。
explicit 修饰的构造函数如何理解?
通过将构造函数声明为explicit(显式)的方式可以抑制隐式转换。也就是说,explicit构造函数必须显式调用。按默认规定,只用传一个参数的构造函数也定义了一个隐式转换。具体参考:C++ explicit关键字详解
std::make_shared 作用是什么?在什么场景下使用?
如有可能,第一次创建内存资源时,请使用 make_shared 函数创建 shared_ptr。 make_shared 异常安全。 它使用同一调用为控制块和资源分配内存,这会减少构造开销。 如果不使用 make_shared,则必须先使用显式 new 表达式来创建对象,然后才能将其传递到 shared_ptr 构造函数。具体参考:如何:创建和使用 shared_ptr 实例
void detach() 作用?
拆离相关联的线程。 操作系统负责释放终止的线程资源。具体参考:thread类-detach
std::unique_lock 作用及应用场景?
表示可进行实例化以创建管理 mutex 锁定和解锁的对象的模板。uniqie_lock 是个类模板,它的功能跟 lock_quard 类似,但比 lock_quard 更灵活。在工作中,一般用 lock_quard (推荐使用)就足够了,但在一些特殊的场景下会用到 uniqie_lock。 lock_quard 取代了 mutex 的 lock() 和 unlock(),在 lock_quard 的构造函数中上锁,在析构函数中解锁,这点其实在 uniqie_lock 中也是一样的。uniqie_lock 在使用上比 lock_quard 灵活,但代价就是效率会低一点,并且内存占用量也会相对高一些。具体参考:unique_lock详解 和 unique_lock 类
std::mutex 作用及应用场景?
Mutex 又称互斥量,C++ 11中与 Mutex 相关的类(包括锁类型)和函数都声明在 <mutex> 头文件中,所以如果你需要使用 std::mutex,就必须包含 <mutex> 头文件。std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。具体参考:C++11 并发指南三(std::mutex 详解)
std::move 与 std::forward 作用及应用场景?
std::forward 比 std::move 逻辑略复杂,std::move 是无条件把参数转换为右值,而 std::forward 在特定情况下才会这样做:仅当参数是用右值初始化时,才会把它转换为右值。它的意义是使外面的函数调用选择接受右值的版本,实际的移动工作是由外面的函数进行的;使用std::forward来转发参数一般被称为完美转发 (也叫精确传递)。具体参考:C++ 理解std::forward完美转发。这里,使用 std::move 将 pool->tasks.front() 装换为右值,从而使得 std::function 类型的 task 调用 function& operator= (function&& rhs); 构造函数,避免资源重复申请创建。详细讨论参考:知乎std::move回答
ThreadPool(ThreadPool&&) = default; 该构造函数是什么含义?
此语句代表显式默认构造函数,而且该构造函数为移动构造函数,移动构造函数是特殊成员函数,它将现有对象数据的所有权移交给新变量,而不复制原始数据。 它采用 rvalue 引用作为其第一个参数,以后的任何参数都必须具有默认值。 **移动构造函数在传递大型对象时可以显著提高程序的效率。**具体参考:显式默认设置的函数和已删除的函数 | Microsoft Learn 和 移动构造函数 (C++) | Microsoft Learn
代码 task_queue_->tasks.emplace(std::forward<F>(task)); 语句如何理解?
首先,task_queue_->tasks 的类型是 std::queue<std::function<void()>>,成员函数 emplace,会在当前的最后一个元素之后,即队列的末尾添加了一个新元素。 这个新元素会采用元素类的构造函数够赞,并且将 std::forward<F>(task)) 作为其构造函数的参数;另外,此处,std::forward<F> 将输入的参数原封不动地传递到下一个函数中,如果输入的参数是左值,那么传递给下一个函数的参数的也是左值;如果输入的参数是右值,那么传递给下一个函数的参数的也是右值。那么,当 task 参数是右值时,完美转发后,将会调用移动构造函数 function( function&& other ); 进行构造。此处,还需更深入理解。可以参考书籍《深入理解C++11:C++11新特性解析与应用》
基于小根堆实现的定时器
小根堆
堆(Heap)是计算机科学中的一种特别的完全二叉树。若是满足以下特性,即可称为堆:“给定堆中任意节点P和C,若P是C的母节点,那么P的值会小于等于(或大于等于)C的值”。若母节点的值恒小于等于子节点的值,此堆称为最小堆(min heap);反之,若母节点的值恒大于等于子节点的值,此堆称为最大堆(max heap)。在堆中最顶端的那一个节点,称作根节点(root node),根节点本身没有母节点(parent node)。参考:堆 - 维基百科
根据上面定义可知,小根堆(min heap)的根节点总是小于等于其他任意节点。
那么,这里为什么要用小根堆实现定时器呢?
首先,定时器和我们大家常用的闹钟类似,记录到时时间,由于,服务器会保持大量的连接,因此,对于每个连接都需要记录一个定期时间(expires),这里采用 C++ 中任何一个容器就可以了;但是,考虑到我们采用定时器是为了将那些已经超时的连接关闭,对于一个记录大量倒计时的记录来说,必然是那些定期时间时间较小的连接,首先到达超时时间,这意味着这些连接距离上次连接活动已经过去了较长时间,因此,我们每次要获取这些定期时间记录中最小记录,判断是否超时,如果小于当前时间,代表已经超时,那么关闭这个 TCP 连接,重复上面至获取的定期时间大于当前时间;另外,由于在 WebServer::Start() 中存在 epoller_->Wait(timeMS) ,这表明主线程会进入超时阻塞中,主动放弃 CPU ,当有事件发生或者到达超时时间才会被操作系统内核主动唤醒,那么,这里的参数 timeMS 如果设置过大,将会导致无法及时关闭超时连接,造成网络连接资源浪费;如果该参数设置过小,将会导致频繁唤醒主线程,导致 CPU 资源浪费。综上,我们每次获取全部连接定时器中剩余时间最短的时间,将此时间设置为 timeMS ,这样,就能及时关闭超时连接,也不会造成资源浪费。
源码解析
下面我们根据源码分析该定时器功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| /*
* @File : heaptimer.h
* @Author : mark
* @Date : 2020-06-17
* @copyleft Apache 2.0
*/
#ifndef HEAP_TIMER_H
#define HEAP_TIMER_H
#include <queue>
#include <unordered_map>
#include <time.h>
#include <algorithm>
#include <arpa/inet.h>
#include <functional>
#include <assert.h>
#include <chrono>
#include "../log/log.h"
typedef std::function<void()> TimeoutCallBack;
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::milliseconds MS;
typedef Clock::time_point TimeStamp;
struct TimerNode {
int id; // 网络套接字描述符
TimeStamp expires; // 到期时间戳
TimeoutCallBack cb; // 到期回调函数
bool operator<(const TimerNode& t) { // TimerNode 小于运算符
return expires < t.expires;
}
};
class HeapTimer {
public:
// 构造函数,并初始化当前vector容器容量为64
HeapTimer() { heap_.reserve(64); }
~HeapTimer() { clear(); }
// 调整网络套接描述符id的连接超时时间为 timeOut
void adjust(int id, int timeOut);
// 添加网络套接描述符id的连接超时时间为 timeOut,并设置超时回调函数
void add(int id, int timeOut, const TimeoutCallBack& cb);
// 删除指定id结点,并触发回调函数
void doWork(int id);
// 清空堆
void clear();
// 清除超时节点
void tick();
// 清楚堆顶节点
void pop();
// 获取最近到期超时连接的剩余时间ms
int GetNextTick();
private:
// 删除节点
void del_(size_t i);
// 节点向上调整
void siftup_(size_t i);
// 节点向下调整
bool siftdown_(size_t index, size_t n);
// 交换两个节点
void SwapNode_(size_t i, size_t j);
// 用 vector 实现的小根堆
std::vector<TimerNode> heap_;
// 记录网络套接描述符到 TimerNode 在 heap_ 中的位置映射关系
std::unordered_map<int, size_t> ref_;
};
#endif //HEAP_TIMER_H
|
HeapTimer 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
| /*
* @File : heaptimer.cpp
* @Author : mark
* @Date : 2020-06-17
* @copyleft Apache 2.0
*/
#include "heaptimer.h"
void HeapTimer::siftup_(size_t i) {
assert(i >= 0 && i < heap_.size());
size_t j = (i - 1) / 2;
while(j >= 0) {
if(heap_[j] < heap_[i]) { break; }
SwapNode_(i, j);
i = j;
j = (i - 1) / 2;
}
}
void HeapTimer::SwapNode_(size_t i, size_t j) {
assert(i >= 0 && i < heap_.size());
assert(j >= 0 && j < heap_.size());
std::swap(heap_[i], heap_[j]);
ref_[heap_[i].id] = i;
ref_[heap_[j].id] = j;
}
bool HeapTimer::siftdown_(size_t index, size_t n) {
assert(index >= 0 && index < heap_.size());
assert(n >= 0 && n <= heap_.size());
size_t i = index;
size_t j = i * 2 + 1;
while(j < n) {
if(j + 1 < n && heap_[j + 1] < heap_[j]) j++;
if(heap_[i] < heap_[j]) break;
SwapNode_(i, j);
i = j;
j = i * 2 + 1;
}
return i > index;
}
void HeapTimer::add(int id, int timeout, const TimeoutCallBack& cb) {
assert(id >= 0);
size_t i;
if(ref_.count(id) == 0) {
/* 新节点:堆尾插入,调整堆 */
i = heap_.size();
ref_[id] = i;
heap_.push_back({id, Clock::now() + MS(timeout), cb});
siftup_(i);
}
else {
/* 已有结点:调整堆 */
i = ref_[id];
heap_[i].expires = Clock::now() + MS(timeout);
heap_[i].cb = cb;
if(!siftdown_(i, heap_.size())) {
siftup_(i);
}
}
}
void HeapTimer::doWork(int id) {
/* 删除指定id结点,并触发回调函数 */
if(heap_.empty() || ref_.count(id) == 0) {
return;
}
size_t i = ref_[id];
TimerNode node = heap_[i];
node.cb();
del_(i);
}
void HeapTimer::del_(size_t index) {
/* 删除指定位置的结点 */
assert(!heap_.empty() && index >= 0 && index < heap_.size());
/* 将要删除的结点换到队尾,然后调整堆 */
size_t i = index;
size_t n = heap_.size() - 1;
assert(i <= n);
if(i < n) {
SwapNode_(i, n);
if(!siftdown_(i, n)) {
siftup_(i);
}
}
/* 队尾元素删除 */
ref_.erase(heap_.back().id);
heap_.pop_back();
}
void HeapTimer::adjust(int id, int timeout) {
/* 调整指定id的结点 */
assert(!heap_.empty() && ref_.count(id) > 0);
heap_[ref_[id]].expires = Clock::now() + MS(timeout);;
siftdown_(ref_[id], heap_.size());
}
void HeapTimer::tick() {
/* 清除超时结点 */
if(heap_.empty()) {
return;
}
while(!heap_.empty()) {
TimerNode node = heap_.front();
if(std::chrono::duration_cast<MS>(node.expires - Clock::now()).count() > 0) {
break;
}
node.cb();
pop();
}
}
void HeapTimer::pop() {
assert(!heap_.empty());
del_(0);
}
void HeapTimer::clear() {
ref_.clear();
heap_.clear();
}
int HeapTimer::GetNextTick() {
tick();
size_t res = -1;
if(!heap_.empty()) {
res = std::chrono::duration_cast<MS>(heap_.front().expires - Clock::now()).count();
if(res < 0) { res = 0; }
}
return res;
}
|
异步日志系统
简介
系统日志是用来记录服务器的运行状态,以保证系统的正常运行,记录的信息如时间日期、客户端的读写操作、当前客户端连接数量、Error与Warn状况等,Webserver是采用单例模式与阻塞队列实现的异步的日志系统,如下为日志的记录情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| 2023-01-28 04:17:37.625250 [info] : ========== Server init ==========
2023-01-28 04:17:37.625274 [info] : Port:1316, OpenLinger: false
2023-01-28 04:17:37.625281 [info] : Listen Mode: ET, OpenConn Mode: ET
2023-01-28 04:17:37.625283 [info] : LogSys level: 1
2023-01-28 04:17:37.625286 [info] : srcDir: /home/andy/Workplace/cpp_advance/cpp14/WebServer/resources/
2023-01-28 04:17:37.625369 [info] : SqlConnPool num: 12, ThreadPool num: 6
2023-01-28 04:17:37.625376 [info] : ========== Server start ==========
2023-01-28 04:17:49.682366 [info] : Client[6](172.17.0.1:60549) in, userCount:1
2023-01-28 04:17:49.685458 [info] : Client[6] in!
2023-01-28 04:17:49.767379 [info] : Client[7](172.17.0.1:64133) in, userCount:2
2023-01-28 04:17:49.772650 [info] : Client[7] in!
2023-01-28 04:17:49.774038 [info] : Client[8](172.17.0.1:2694) in, userCount:3
2023-01-28 04:17:49.775470 [info] : Client[8] in!
2023-01-28 04:17:49.777246 [info] : Client[9](172.17.0.1:6278) in, userCount:4
2023-01-28 04:17:49.779328 [info] : Client[9] in!
2023-01-28 04:17:49.781121 [info] : Client[10](172.17.0.1:7302) in, userCount:5
2023-01-28 04:17:49.782755 [info] : Client[10] in!
2023-01-28 04:17:49.888415 [info] : Client[11](172.17.0.1:11398) in, userCount:6
2023-01-28 04:17:49.890183 [info] : Client[11] in!
2023-01-28 04:19:00.082966 [info] : Client[8] quit!
2023-01-28 04:19:00.086492 [info] : Client[8](172.17.0.1:2694) quit, UserCount:5
2023-01-28 04:19:00.087991 [info] : Client[9] quit!
2023-01-28 04:19:00.088420 [info] : Client[9](172.17.0.1:6278) quit, UserCount:4
2023-01-28 04:19:00.089962 [info] : Client[11] quit!
2023-01-28 04:19:00.091502 [info] : Client[11](172.17.0.1:11398) quit, UserCount:3
2023-01-28 04:19:00.092822 [info] : Client[10] quit!
2023-01-28 04:19:00.094522 [info] : Client[10](172.17.0.1:7302) quit, UserCount:2
2023-01-28 04:19:00.095606 [info] : Client[6] quit!
2023-01-28 04:19:00.096684 [info] : Client[6](172.17.0.1:60549) quit, UserCount:1
2023-01-28 04:19:00.316124 [info] : Client[7] quit!
|
源码解析
Log 类在被实例化时系统有且最多只有一个 Log 类的对象即单例模式,它是如何实现的呢?
首先会将 Log 类的构造函数、拷贝构造函数和赋值运算符重载函数私有化,由此外界就不能直接创建Log类对象,这时我们需要一个静态 Log 类型的对象,以便系统使用同一的类对象,而外界想要获取静态 Log 类型的对象,就需要定义一个静态成员方法,因为只有静态成员方法才能访问静态成员变量,由此实现 Log 类的单例模式。
Log 类及 Instance 函数的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| class Log {
public:
void init(int level, const char* path = "./log",
const char* suffix =".log",
int maxQueueCapacity = 1024);
static Log* Instance();
static void FlushLogThread();
void write(int level, const char *format,...);
void flush();
int GetLevel();
void SetLevel(int level);
bool IsOpen() { return isOpen_; }
private:
Log();
void AppendLogLevelTitle_(int level);
virtual ~Log();
void AsyncWrite_();
private:
static const int LOG_PATH_LEN = 256;
static const int LOG_NAME_LEN = 256;
static const int MAX_LINES = 50000;
const char* path_;
const char* suffix_;
int MAX_LINES_;
int lineCount_;
int toDay_;
bool isOpen_;
Buffer buff_;
int level_;
bool isAsync_;
FILE* fp_;
std::unique_ptr<BlockDeque<std::string>> deque_;
std::unique_ptr<std::thread> writeThread_;
std::mutex mtx_;
};
Log* Log::Instance() {
static Log inst;
return &inst;
}
|
系统中有4种类型的日志,分别是 LOG_DEBUG 、 LOG_INFO 、 LOG_WARN 与 LOG_ERROR ,它们共同使用 LOG_BASE,以level来区分不同级别的日志,以实现代码的复用。同时自己初始设置的日志等级可以控制不同级别的日志是否被记录,宏定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 语言设置为 C# 才会有颜色高亮
#define LOG_BASE(level, format, ...) \
do {\
Log* log = Log::Instance();\
if (log->IsOpen() && log->GetLevel() <= level) {\
log->write(level, format, ##__VA_ARGS__); \
log->flush();\
}\
} while(0);
#define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0);
#define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0);
#define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0);
#define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0);
|
在 webserver.cpp 中,如果开启日志即 openLog = true 时,则会先调用 init() 去初始化日志信息,当 maxQueueSize > 0 时则会创建一个阻塞队列与写线程,值得注意的是日志系统是单线程模式,因为并不需要较高的并发量,写线程的回调函数则当阻塞队列不空时持续向 FILE* 类型的指针 fp_ 写入字符串,再使用 fflush(fp_) 刷新至文件中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| void Log::init(int level = 1, const char* path, const char* suffix,
int maxQueueSize) {
isOpen_ = true;
level_ = level;
if(maxQueueSize > 0) {
isAsync_ = true;
if(!deque_) {
unique_ptr<BlockDeque<std::string>> newDeque(new BlockDeque<std::string>(maxQueueSize));
deque_ = move(newDeque);
std::unique_ptr<std::thread> NewThread(new thread(FlushLogThread));
writeThread_ = move(NewThread);
}
} else {
isAsync_ = false;
}
lineCount_ = 0;
time_t timer = time(nullptr);
struct tm *sysTime = localtime(&timer);
struct tm t = *sysTime;
path_ = path;
suffix_ = suffix;
char fileName[LOG_NAME_LEN] = {0};
snprintf(fileName, LOG_NAME_LEN - 1, "%s/%04d_%02d_%02d%s",
path_, t.tm_year + 1900, t.tm_mon + 1, t.tm_mday, suffix_);
toDay_ = t.tm_mday;
{
lock_guard<mutex> locker(mtx_);
buff_.RetrieveAll();
if(fp_) {
flush();
fclose(fp_);
}
fp_ = fopen(fileName, "a");
if(fp_ == nullptr) {
mkdir(path_, 0777);
fp_ = fopen(fileName, "a");
}
assert(fp_ != nullptr);
}
}
|
当使用 LOG_DEBUG 、 LOG_INFO 、 LOG_WARN 与 LOG_ERROR 时,则会宏替换为 LOG_BASE , LOG_BASE 继续宏替换至执行代码,然后依据日志开关与等级是否记录,如果记录则会调用 write() 函数,在 write() 函数中会制作日志记录如日志日期、日志行数、日志内容等至 buff_ 中,然后添加至阻塞队列中,在 AsyncWrite_() 函数的循环能继续向下执行,向 FILE* 类型的指针 fp_ 写入字符串,然后再调用 flush() 函数刷新至日志文件中,这是日志记录的整个过程,可结合上述的具体实现。而 write() 函数可自行查看源代码。
总结与感悟
- 目前来说,好好完善并思考这个项目就可以达到对于
C++14、Linux 网络编程综合学习与训练的目的了,后面进阶还需要真正参与到工业生产代码中,在实践中认真学习与总结。 - 这种比较偏底层的网络编程,对于应用层来说已经有了很多成熟的软件库,大多数时候不用修改和优化。
源码阅读进阶
参考资料
扩展知识
- NanoLog:一个非常高性能的纳秒级c++日志记录系统,它提供了一个简单的类似print的API,在7纳秒的中位数延迟下实现了超过8000万条日志/秒。
- args:C++实现的命令行参数解析器。