
算法简述
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
应用场景
考虑这么一种场景:我们有三台缓存服务器,编号node0、node1、node2,现在有 3000 万个 key,希望可以将这些个 key 均匀地缓存到三台机器上,你会想到什么方案呢?
我们可能首先想到的方案是:取模算法hash(key)% N,即:对 key 进行 hash 运算后取模,N 是服务器节点的数量。
这样,对 key 进行 hash 后的结果对 3 取模,得到的结果一定是 0、1 或者 2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题;
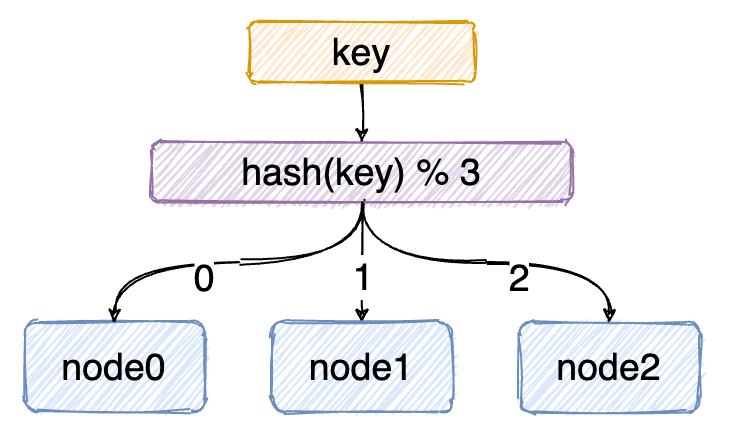
取模算法虽然使用简单,但对机器数量取模,在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事,那么,当服务器数量 N 发生变化后hash(key)% N 计算的结果也会随之变化!
这样,如果一个服务器节点因为故障宕机了(挂了)或者因为业务量激增而增加一个服务器节点,此时,因为服务器节点数量 N 的改变,导致大量 key 通过取模算法hash(key)% N计算得到的缓存服务节点发生改变,那么之前缓存 key 的数据也会失去作用,从而导致大量缓存在同一时间失效,造成缓存的雪崩,进而导致整个缓存系统的不可用,这对业务来说是不可接受的。
为了解决并优化上述情况,一致性 hash 算法应运而生~~
关键思想
一致性 Hash 就是:将原本单个点的 Hash 映射,转变为了在一个环上的某个片段上的映射!
算法过程
第一步:建立一致性hash环
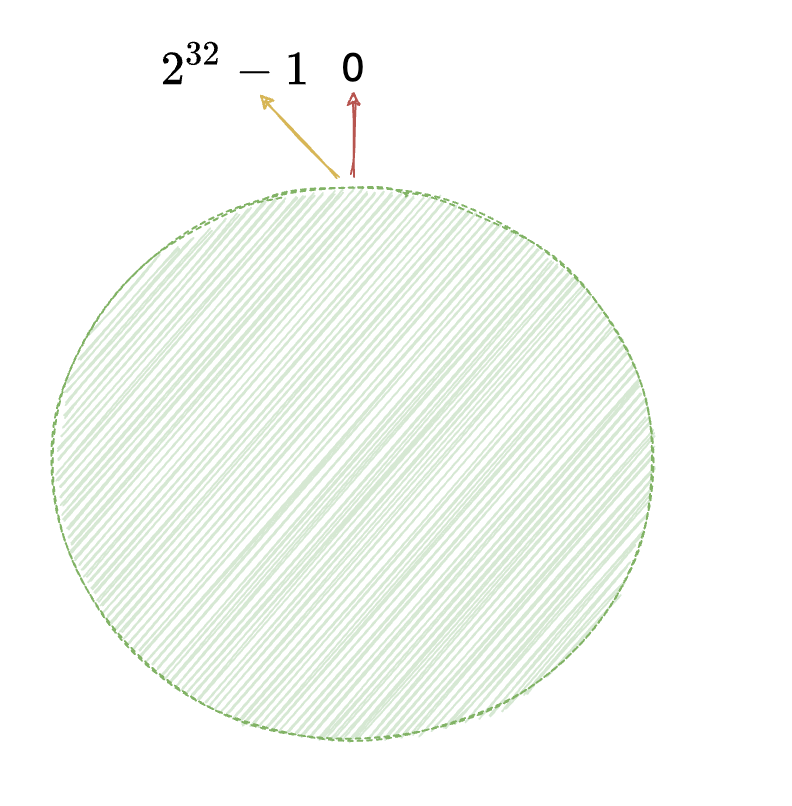
一致性hash算法通过一个叫做一致性hash环的抽象数据结构实现,不同于按服务器数量取模,一致性 hash 是对固定值 $2^{32}$ 取模,具体来讲,按照常用的hash算法将对应的key哈希到一个具有2^32次方个桶的空间中,即 $0 \sim 2^{32}-1$的整数空间中。现在我们可以将这些数字头尾相连,抽象成一个闭合的环形,以顺时针排列。如下:
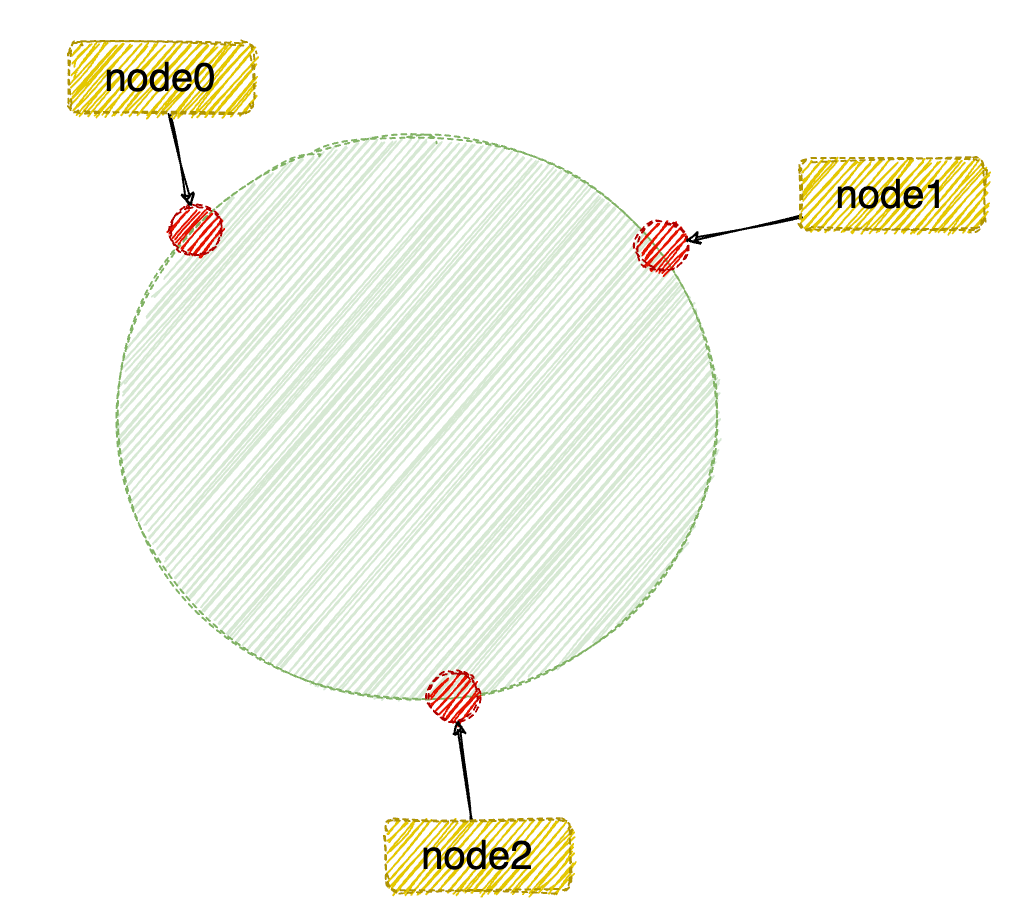
第二步:将服务器节点映射到 hash 环中
对服务器节点进行映射,使用 hash(节点ip)% 2^32,即:使用服务器 IP 地址进行 hash 计算,用哈希后的结果对$2^{32}$取模,结果一定是一个 $0$ 到$2^{32}-1$之间的整数;得到的整数在hash环中的位置代表了一个服务器节点,如图,依次将 node0、node1、node2缓存服务器节点映射到hash环后的结果。
第三步:将所需缓存对象的key映射到服务器节点
在对所需要缓存对象的 key 进行映射到具体的服务器时,需要首先计算 key 的 hash 值:hash(key)% 2^32。将 key 映射至服务器遵循这样的逻辑,从缓存对象 key 的 hash 值 keyN 位置开始,沿顺时针方向遇到的第一个服务器节点,即是当前对象将要缓存的服务器节点。
注:此处的
hash函数可以和之前计算服务器节点映射至 hash 环的函数不同,只要保证取值范围和 Hash 环的范围相同即可(即:2^32)。
举例说明:假设我们有 “semlinker”、“kakuqo”、“lolo”、“fer” 四个 key 代表的四个需要缓存的对象,分别简写为 o1、o2、o3 和 o4;使用哈希函数计算每个对象的 hash 值,值的范围是 [0, 2^32-1] 如下:
| |
将 k1 、k2 、k3 、k4 位置对应到步骤2中的 hash 环中,如下:
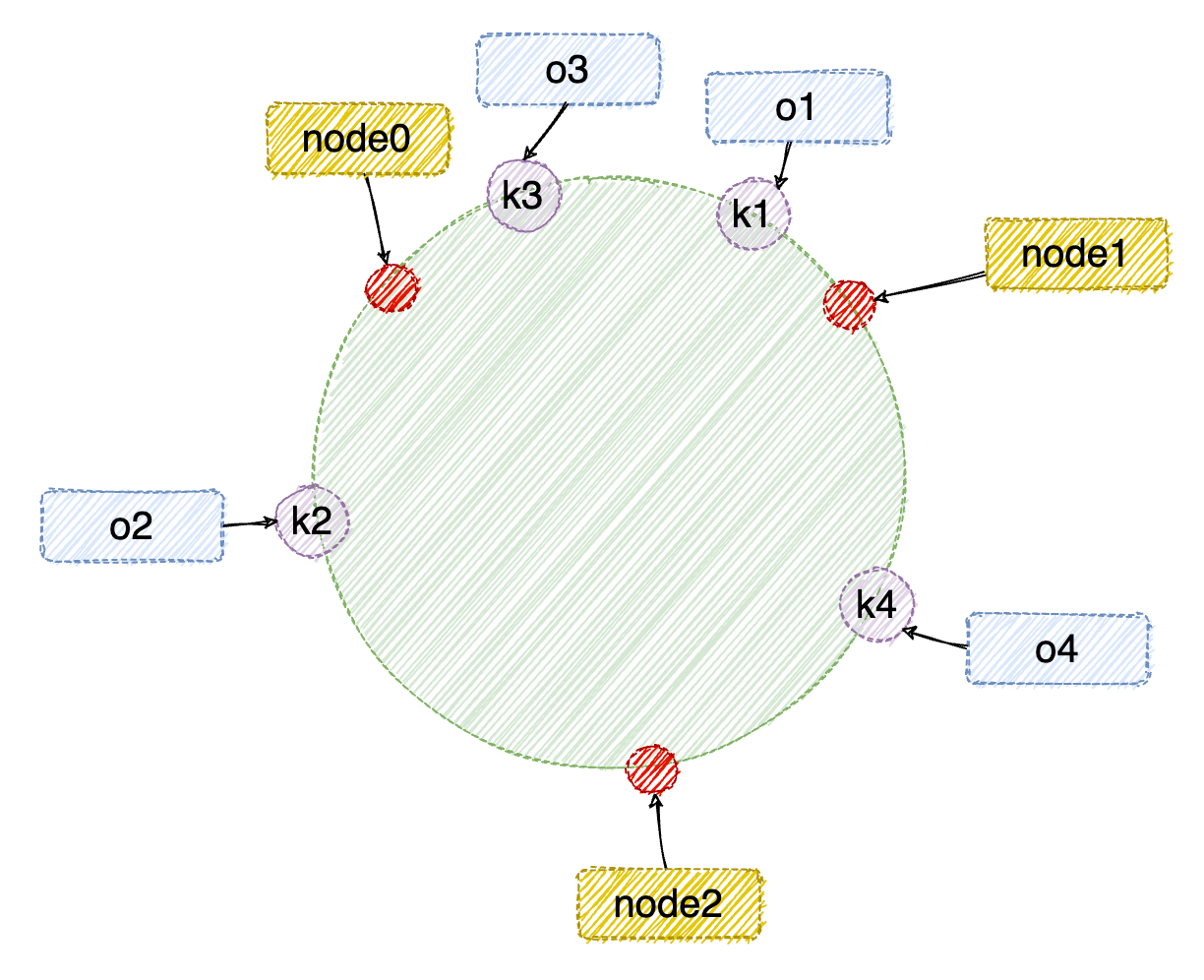
按照上面的顺时针映射到服务器节点,得到的四个对象应该缓存的服务器节点为 o1 -> node1 、o3 -> node1 、o4 -> node2、o2 -> node0,详细如下图:
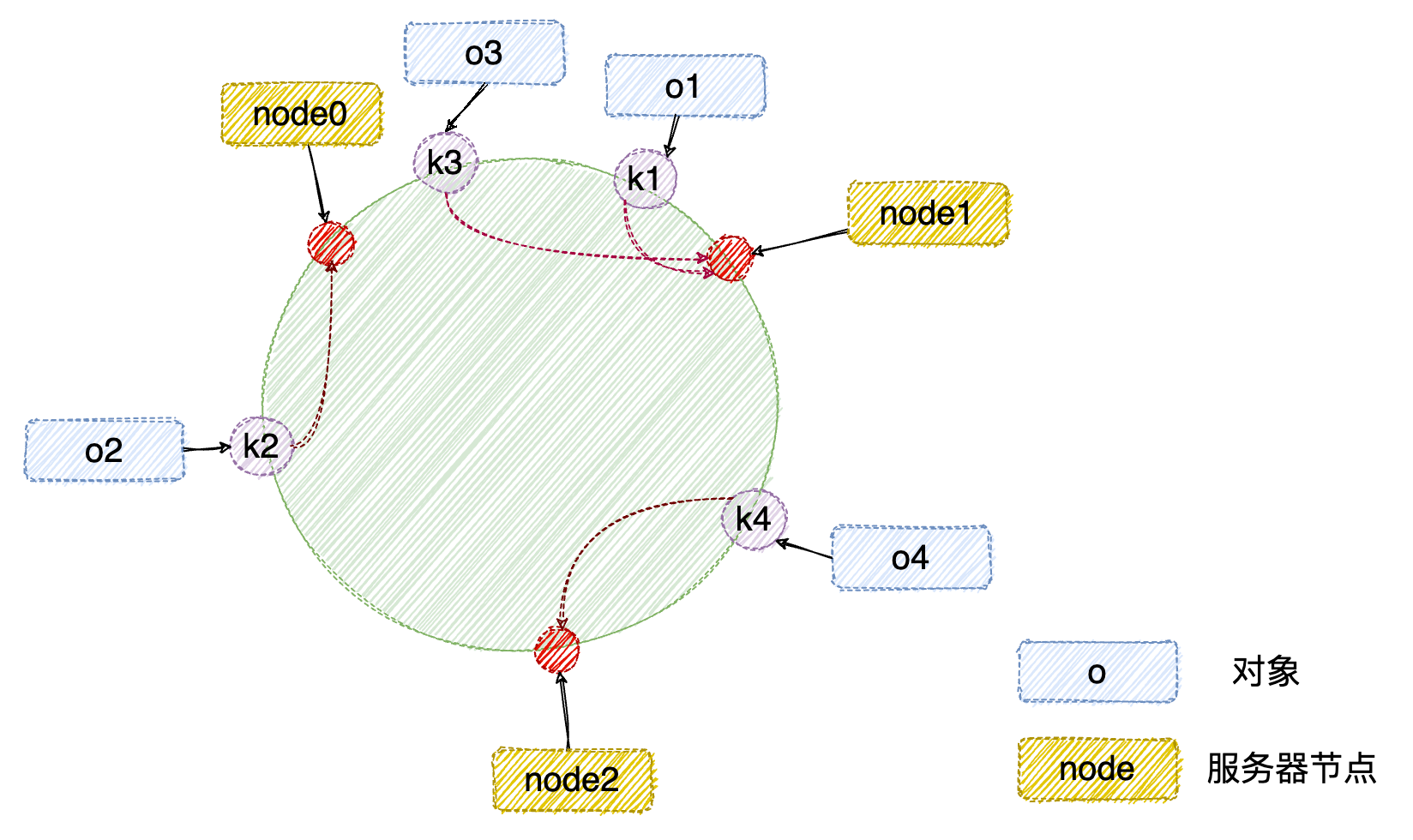
服务器扩缩容场景
当我们面临服务器节点扩缩时,该算法能够保证大部分对象仍然存储在原有的服务器节点上,避免大规模缓存失效。
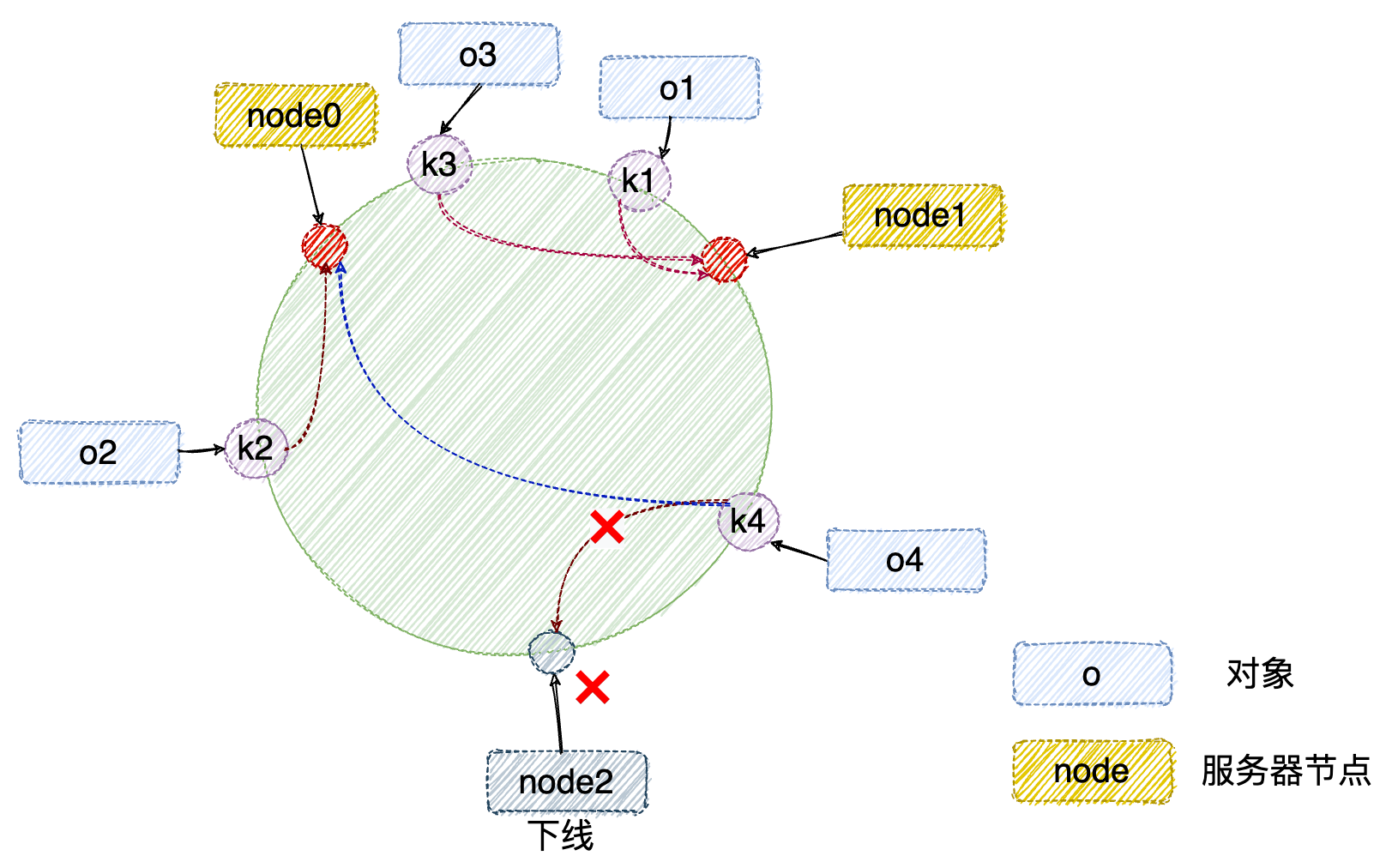
1)服务器减少
假设 node2 服务器出现故障导致服务下线,这时原本存储于node2 服务器的对象 o4,需要被重新分配至 node0 服务器,其它对象仍存储在原有的机器上,此时受影响的缓存数据只有缓存到 node1 和 node2 服务器之间的部分数据~~
2)服务器增加
假如业务量激增,我们需要增加一台服务器 node3,经过同样的 hash 运算,该服务器最终落于 node0 和 node1 服务器之间,具体如下图所示:
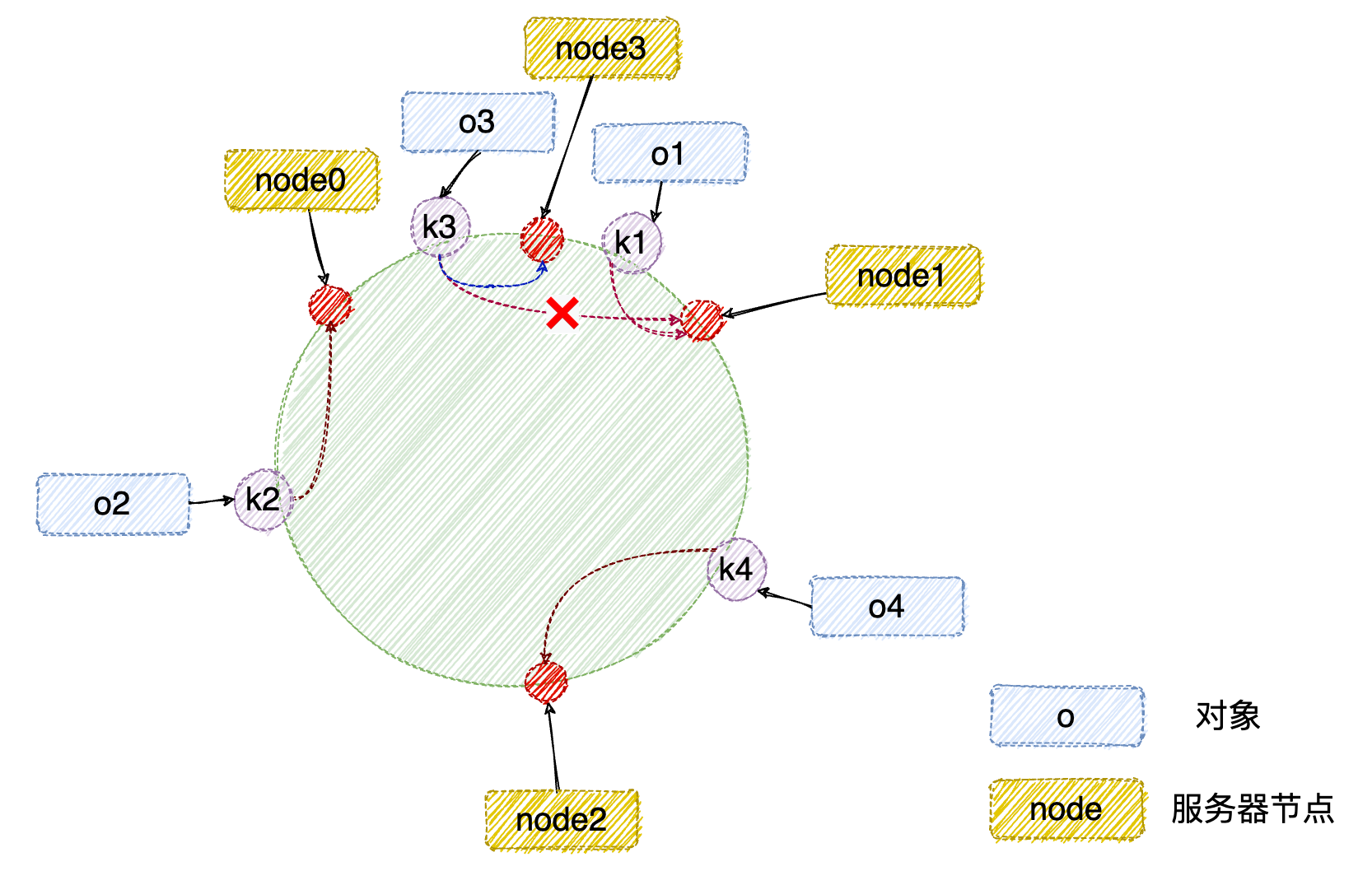 此时,只有
此时,只有 node0 和 node1 服务器之间的部分对象需要重新分配;在上面示例中只有 o3 对象需要重新分配,即它被重新缓存到 node3 服务器节点上。
数据偏斜与服务器性能平衡问题
在上面给出的例子中,各个服务器几乎是平均被均摊到 hash 环上,但是在实际场景中很难选取到一个 Hash 函数这么完美的将各个服务器比较均匀地散列到 hash 环上,此时,在服务器节点数量太少的情况下,很容易造成因节点分布不均匀而造成数据倾斜问题。
如下图,被缓存的对象大部分缓存在 node2 服务器上,导致其他节点资源浪费,系统压力大部分集中在node2节点上,这样的集群是非常不健康的。
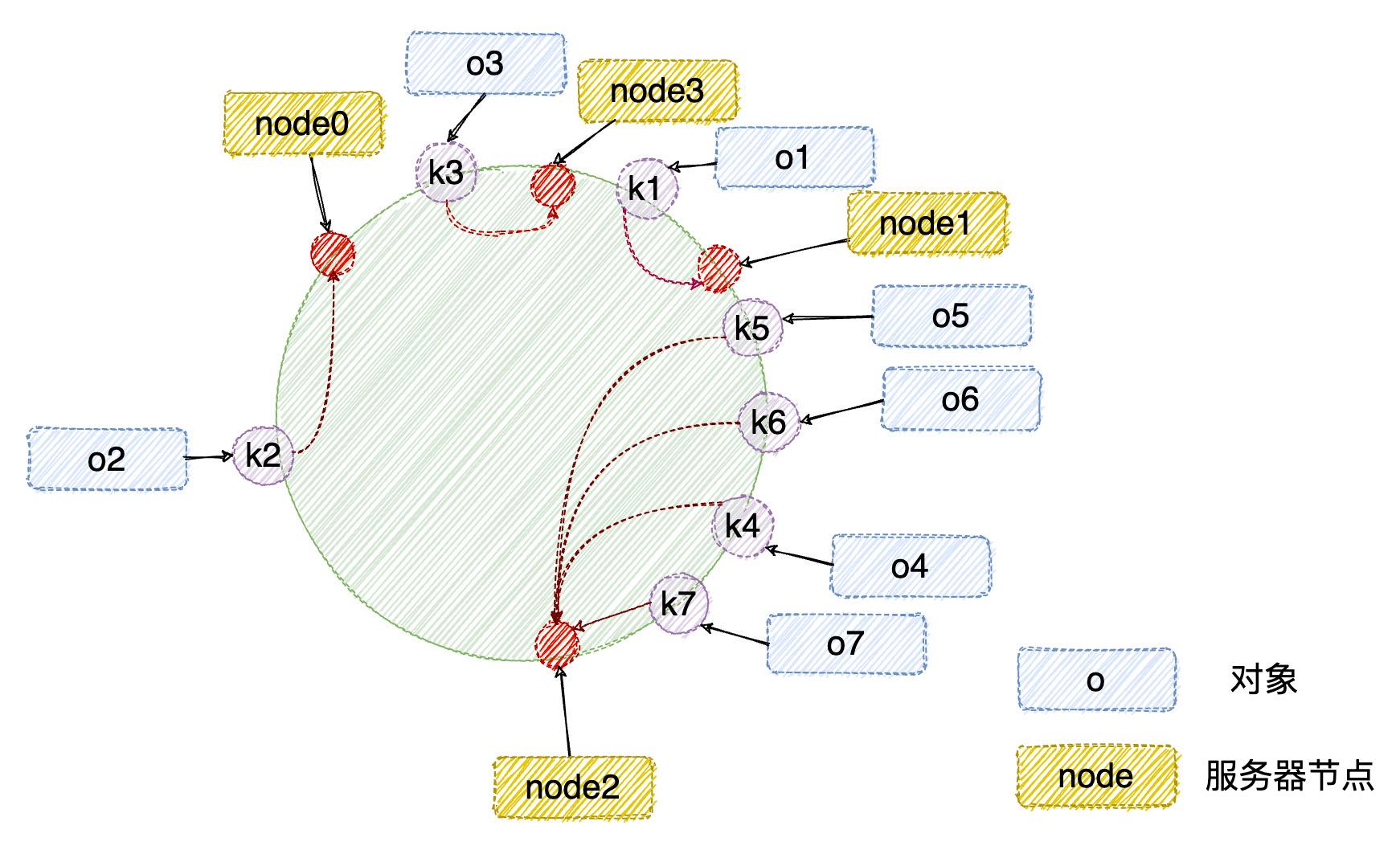
另外,还存在另一个问题:在上面新增服务器 node3 时,node3 只分担了 node1 服务器的负载,服务器 node0 ,尤其是 node2 并没有因为 node3 服务器的加入而减少负载压力;如果新增的 node3 服务器的性能与原有服务器的性能一致甚至可能更高,那么这种结果并不是我们所期望的。
虚拟节点的引入
为了解决上面的问题,我们可以通过:引入虚拟节点来解决负载不均衡的问题。
将每台物理机器虚拟为一组虚拟机器,一个实际物理服务器节点(机器)对应了若干个“虚拟节点”,将虚拟机器哈希到 Hash 环上,如果需要确定对象即将缓存的服务器节点,先确定对象的虚拟节点,再由虚拟节点确定物理服务器节点。
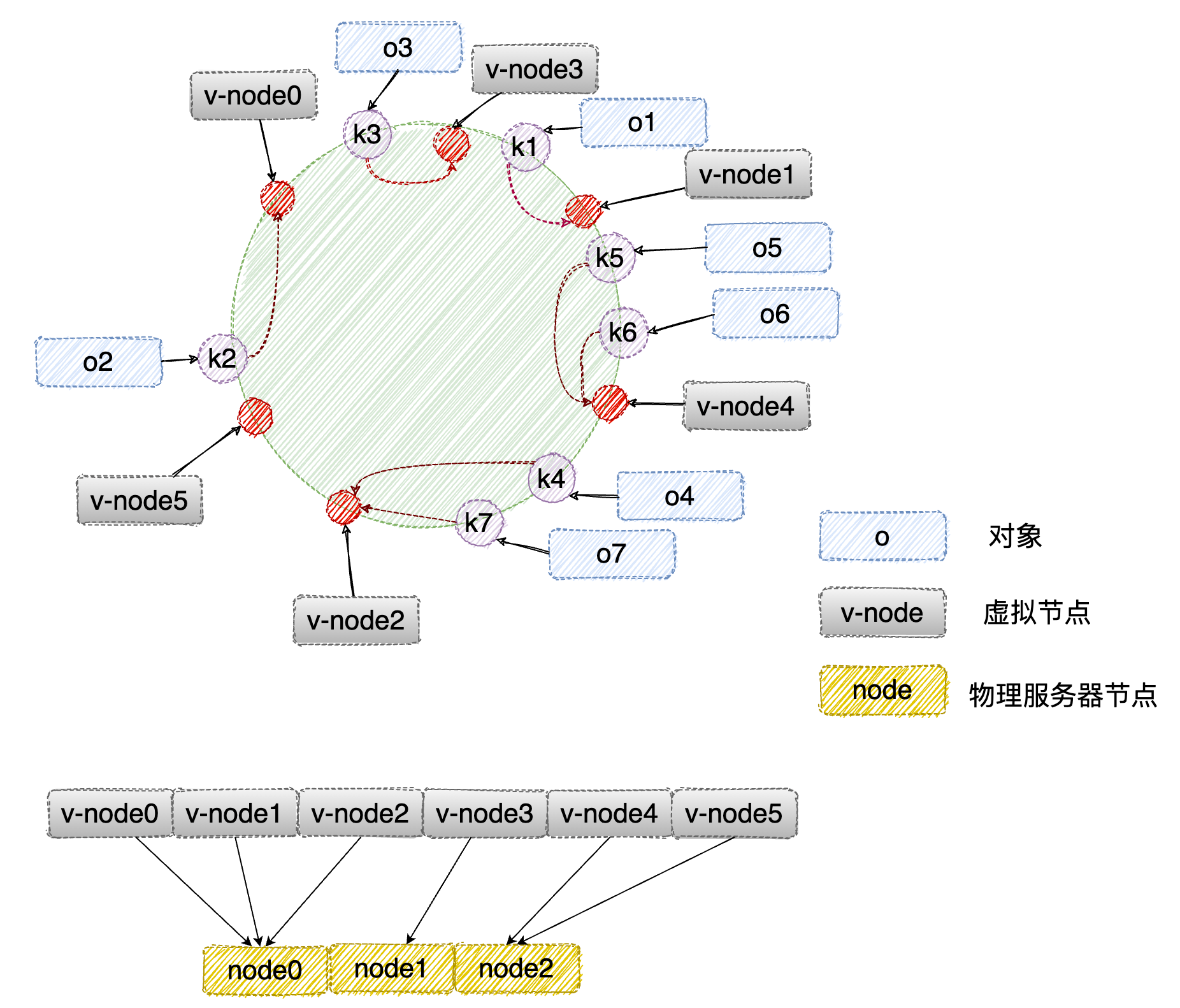
虚拟节点的计算
代码示例
存在问题
应用案例
- Memcached 一个开源、高性能、分布式内存缓存系统,旨在通过减少数据库负载来加速动态 Web 应用程序。
- Redis 一个开源的基于内存的数据库,常用作键值存储、缓存和消息队列等。
- Dubbo 一个分布式服务框架。
补充学习
- 分布式哈希(DHT)
- CARP